Die Phonotaktik ist das Teilgebiet der Linguistik, welches die Prinzipien analysiert, nach der eine Sprache einzelne Laute zu übergeordneten Einheiten wie Silben oder Wörtern kombiniert. So ist beispielsweise die Lautfolge /pt/ im Polnischen wie in ptak „Vogel“ im Wortanlaut möglich, wohingegen das Deutsche sie nur am Wortende erlaubt, beispielsweise in (es) klappt. Dass solche Regeln zwischen Standardsprachen und Dialekten unterschiedlich ausfallen können, zeigen Beschreibungen in einzelnen Ortsgrammatiken (z. B. Winteler 1876). Jedoch gibt es bislang keine Arbeiten, die regionale Phonotaktik vergleichend beschreiben, was auch auf einen Mangel geeigneter Daten zurückgeführt werden kann. Denn obwohl es zahlreiche Korpora zum (gesprochenen) Deutschen gibt (siehe Kupietz & Schmidt 2018), sind diese entweder nicht regional spezifiziert oder sie sind nicht phonotaktisch aufbereitet. Diese Lücke soll durch das von der Deutschen Forschungsgemeinschaft (DFG) geförderte Projekt PhonD2 geschlossen werden; eine frei zugängliche Online-Datenbank mit der die phonotaktischen Strukturen und Besonderheiten der Dialekte von 172 Orten in Deutschland untersucht werden können.
Datengrundlage
Die für das PhonD2-Korpus verwendeten Audiodateien wurden aus den Beständen des Marburger Phonetischen Archivs (MRPhA) ausgewählt. Dabei handelt es sich um Aufnahmen der 40 Wenkersätze, die zwischen 1956 und 1996 in ganz Deutschland erhoben wurden. Zudem wurden mit denselben Personen auch Interviews zu verschiedenen lebensrelevanten Themen wie Beruf, Hobbies, Feste etc. durchgeführt. Die Wenkersätze, die zum Standardinstrumentarium der Deutschen Dialektologie gezählt werden können, erlauben einen direkten Vergleich auf Wortebene, wohingegen die Interviews eine breitere Perspektive auf die gesprochene Sprache ermöglichen. Insgesamt beinhaltet das PhonD2-Korpus über 20 Stunden Material von 172 Orten in ganz Deutschland.
Datenbearbeitung
Die ausgewählten Audiodateien wurden von studentischen Hilfskräften in der Lautschrift SAMPA transkribiert. Um eine hohe und vergleichbare Qualität des transkribierten Materials sicherzustellen, erfolgte auf Grundlage des aktuellen Forschungsstandes eine Einarbeitung in die den jeweiligen Dialektraum kennzeichnenden sprachlichen Besonderheiten. Zudem wurden für die Interviews vorab orthographische Übersetzungen von Dialektsprechern aus den jeweiligen Regionen erstellt, die von den Hilfskräften als Hilfestellung genutzt wurden. Zudem wurde jede fertig bearbeitete Aufnahme nochmals von den Projektmitarbeiterinnen und ‑mitarbeitern manuell nachkorrigiert. Die Wenkersätze wurden vollständig transkribiert, jedoch wurde aufgrund der umfangreichen Datenmenge der Fokus bei den Interviews auf die Transkription von Nomen, Verben, Adjektiven, Adverbien und Numeralia gelegt. Die transkribierten Wörter wurden mithilfe eines regelbasierten Algorithmus silbifiziert und mit primärem Wortakzent versehen. Zusätzlich zur ursprünglichen SAMPA-Transkription wurden die Wörter in IPA-Lautschrift konvertiert. So wird beispielsweise aus dem ursprünglich transkribierten Wort [mOId@] (zentralhessisch müde) dann [ˈmɔɪ̯.də]. Im nächsten Schritt werden maschinell phonotaktisch relevante Informationen ermittelt, wie etwa die CV-Strukur ([ˈmɔɪ̯.də] ∼ CVV.CV), eine Kategorisierung nach den Lautgruppen Plosive ℗, Affrikaten (A), Frikative (F), Nasale (N), Liquide (L), Gleitlaute (G), Kurzvokale (V), Langvokale (Vː) und Diphthonge (VV) ([ˈmɔɪ̯.də] ∼ NVV.PV), absteigende Sonoritätswerte ([ˈmɔɪ̯.də] ∼ 51.61) und starke und schwache Silben ([ˈmɔɪ̯.də] ∼ s.w). Dazu kommt die morphologische Bearbeitung, zu der das automatische, manuell nachkorrigierte POS-Tagging mit dem Klassifikationswerkzeug TreeTagger (Schmid 1995) und die Klassifikation von Morphemen gehört.
Webseite
Die Wenker-Daten sind bereits online über die Projektseite https://regionalsprache.de/phond2/ zugänglich; die Interviews werden aktuell noch bearbeitet und werden nach Überprüfung und Fertigstellung ebenfalls ergänzt. Die Webseite bietet zweierlei Zugänge auf die Daten: Der geographische Zugang bietet einen Überblick über alle Aufnahmeorte. Hier kann entweder per Klick auf die interaktive Karte oder über eine Suchmaske auf das Datenmaterial der individuellen Orte zugegriffen werden.
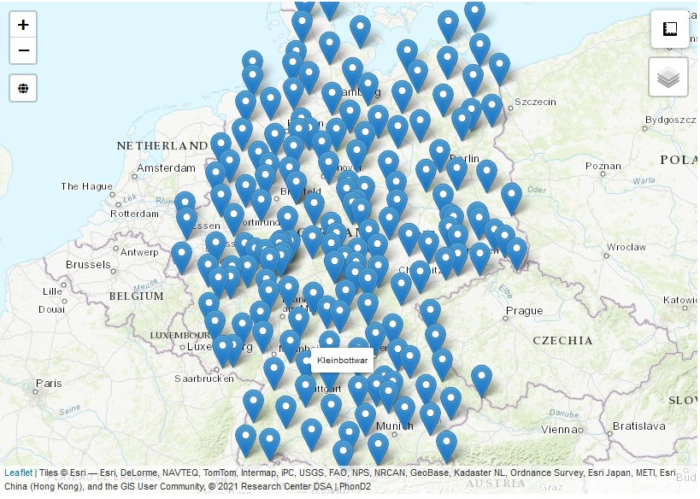
Abb.1: Interaktive Karte für den geographischen Zugang
Der wortbasierte Zugang ermöglicht eine Suche nach spezifischen Wörtern, erlaubt aber auch das Herausgreifen nach Wortklasse (Lexem oder Grammem) und Wortart, wobei auch nach POS-Tags gemäß des STTS (Schiller et al. 1999) gesucht werden kann.
Abb. 2: Suchmaske des wortbasierten Zugangs
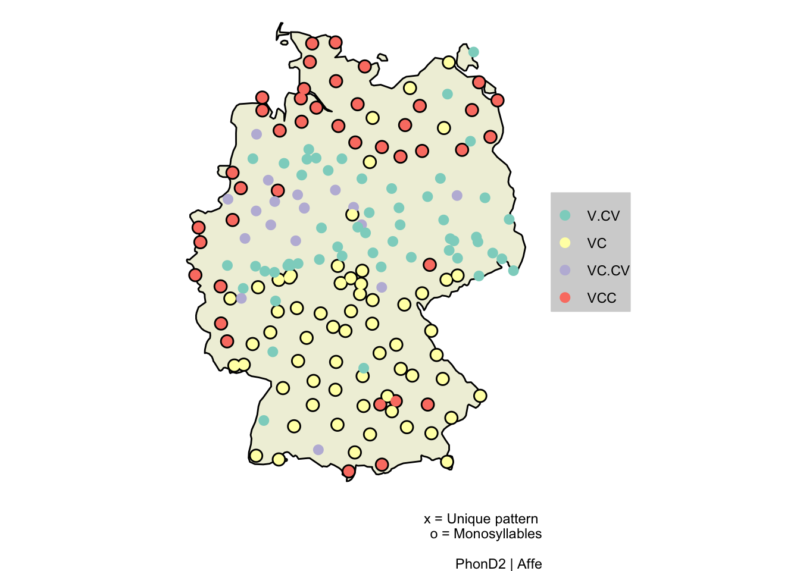
Der Klick auf ein Lemma, z. B. Affe, führt zu einer Karte die einen Überblick über regionale Unterschiede in der CV-Struktur bietet. Jede CV-Struktur ist mit einer eigenen Farbe gekennzeichnet, zusätzlich sind einsilbige Realisierungen durch einen schwarzen Kreis hervorgehoben. Dies visualisiert bei der untenstehenden Affe-Karte die Regionen, in denen Schwa-Apokope ([af] vs. [ˈa.fə]) und Einsilblerdehnung ([af] vs. [aːp]) auftritt (vgl. Schirmunski 1962 und Lameli 2022).
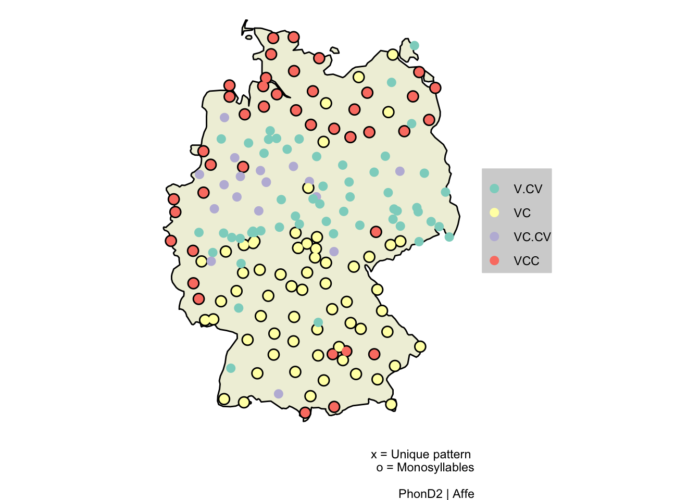
Abb. 3: Regionale Verteilung der CV-Struktur für das Wort Affe
Die Karte wird durch eine weitere Suchmaske ergänzt, die sämtliche Realisierungen des Wortes Affe anzeigt. Es kann nach bestimmten Lauten gesucht werden, aber auch nach Silbenzahl, CV-Struktur, Silbenschema, Sonorität und starker und schwacher Silbe.
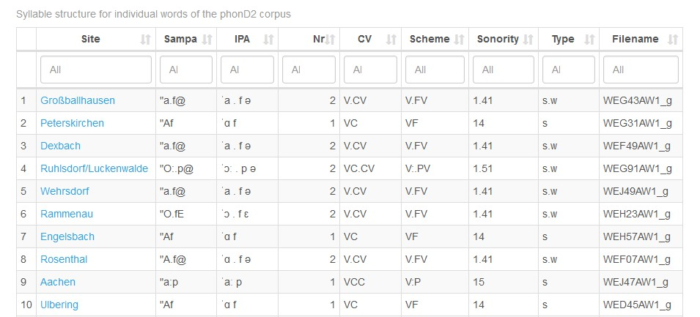
Abb. 4: Suchmaske für das Wort Affe
Neben diesem ort- und wortspezifischen Zugriff bietet die Webseite noch einen Überblick über allgemeine Lauthäufigkeiten im Korpus, aber auch über Lautsequenzen in Form von Trigrammen, für die zusätzlich noch eine Suchfunktion verfügbar ist.
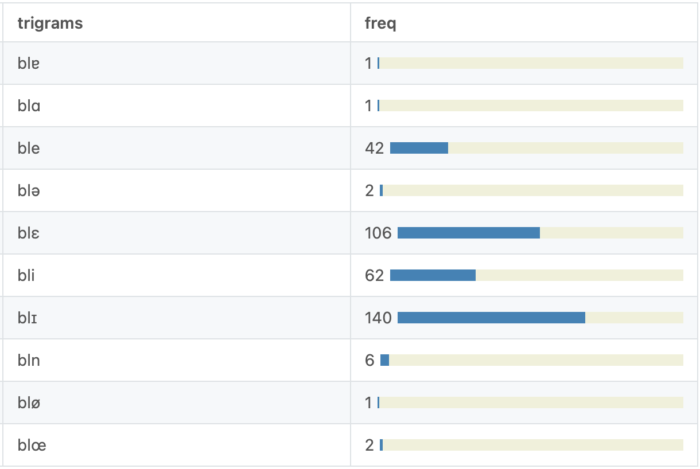
Abb. 5: Trigramme mit [l] als zweitem Laut
Fazit
Das PhonD2-Korpus bietet eine Vielzahl an Möglichkeiten zur Analyse phonotaktischer Strukturen der Dialekte des Deutschen. Diese Ressource bietet sich sowohl für die wissenschaftliche Nutzung an, aber auch für dialektologisch interessierte Personen jeder Art.
Literatur
Kupietz, Marc / Thomas Schmidt (2018): Korpuslinguistik. Berlin/Boston: De Gruyter. https://library.oapen.org/handle/20.500.12657/59516
Lameli, Alfred (2022): Remarks on the consistency of schwa apocope in the geography of German dialects. In: Nevaci, M. / Floarea, I / Farcaş, J‑M (Hg.): Ex Oriente lux. In honorem Nicolae Saramandu. Alessandria: Edizioni dell’Orso. 683–702.
Schmid, Helmut (1995): Improvements in Part-of-Speech Tagging with an Application to German. Dublin: Proceedings of the ACL SIGDAT-Workshop.
Schiller, Anne / Simone Teufel / Christine Stöckert (1999): Guidelines für das Tagging deutscher Textcorpora mit STTS (kleines und großes Tagset). Tübingen: Universität Tübingen.
Schirmunski, Viktor M. (1962): Deutsche Mundartkunde. Vergleichende Laut- und Formenlehre der deutschen Mundarten. Lausanne: Peter Lang.
Winteler, Jost (1876): Die Kerenzer Mundart des Kantons Glarus. In ihren Grundzügen dargestellt. Leipzig/Heidelberg: Winter.
Diesen Beitrag zitieren als:
Link, Samantha & Bunkov, Valeria. 2023. PhonD2: Eine Datenbank zur Phonotaktik der Dialekte in Deutschland. In: Sprachspuren: Berichte aus dem Deutschen Sprachatlas 3(7). https://doi.org/10.57712/2023-07