
This article presents a morphological analysis of 3500 Persian derived nouns (i.e. the Farsi language) combined with their semantic interpretation. These nouns are documented in the computer system FarsNet offering a computational codification (so called wordnets) that specifies morphological relations between classes of derived nouns and their bases. A comprehensive and detailed description of the relevant linguistic levels is a prerequisite for achieving progress in natural language processing (NLP).
WordNets are lexical ontologies relying on semantic and morphological descriptions and formulations (an example is provided in Figure 1). FarsNet has been established in 2009 by the NLP research lab of the Shahid Beheshti University in Teheran and its design principles follow those of other comparable resources such as Princeton WordNet, EuroWordNet and BalkaNet (Shamsfard et al. 2010; those who are familiar with Farsi are referred to the FarsNet page). Besides semantic relations (synonymy, hypernymy, hyponymy, meronymy and antonymy) and morphological relations (derivation), some additional conceptual relations such as domain and related to, have been devised in FarsNet. An example is provided with Figure 1 showing the semantic net of the word “shir”, which is a polysemic noun with the meanings ‘lion’, ‘Leo’ (constellation), ‘powdered milk’, ‘brave’, ‘faucet’, ‘plant sap’, ‘obverse’, ‘mother’s milk’, ‘milk’ all of them with individual semantic relations. Currently (2021), FarsNet has more than one hundred thousand entries, organized in almost nine thousand synsets. A synset (or synonym set) is defined as a set of one or more synonyms that are interchangeable in some context without changing the truth value of the proposition in which they are embedded (Shamsfard et al.2010).
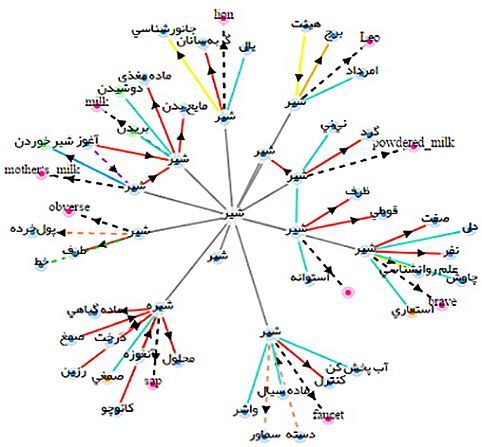
In my own work, the morphological and semantic relations are considered at the word level (and not at the synset) in order to achieve a cross-linguistic validity even if the morphological aspect of the relation is not the same in the studied languages. In order to provide an overall view at the data, it has been classified into sixteen semantic groups based on general base concepts and some subgroups which have been defined for each section and word. Semantic categories (beginner) have been analyzed in a corpus based on Princeton WordNet (PWN) standards (for the semantic categories following the PWN standard see Table 1). After the calculation of their frequency, they have been classified into more nine categories.
| 1. act | 6. cognition | 11. location | 16. plant | 21. shape |
| 2. animal | 7. communication | 12. motive | 17. possession | 22. state |
| 3. artifact | 8. event | 13. object | 18. process | 23. substance |
| 4. attribute | 9. feeling | 14. person | 19. quantity | 24. time |
| 5. boda | 10. group | 15. phenomenon | 20. relation | 25. food |
FarsNet Word Entries
Every word entry of the particular word net include a phonological transcription together with information on the parts of speech (PoS), synonyms and their synset classifications, word meaning and an example. A beginner will be selected for each lexeme. According to Miller et al. (1990) a beginner is a primitive semantic component of any word in its hierarchically structured semantic field. Beginners could be used in the recognition of the domain of a synset. Different syntactic types can be related to each other by mapping each entry to its corresponding concept in Princeton WordNet (Shamsfard et al., 2010). The synsets which do not fall into any of the above categories will get the label nothing (an editor app was formulated in the NlP laboratory, which is shown in Figure 2).
The semantic relations are also established among the synsets with the same PoS. Synsets with different PoS will get labels such as related to. There are three possible choices for mapping a synset to the corresponding one in Princeton WordNet: equivalence mapping, near-equivalence mapping and no-mapping. Finally, the morphological relations among senses, such as derivational relations, are marked.
Besides specifying a noun type (such as common, proper, countable, uncountable, pronoun, number or infinitive), a classification on the basis of some more general semantic features (such as belonging to human, animal, location or time) is provided.
According to Deléger et al. (2009), a morpho-semantic process decomposes derived words, compounds and complex words into their base components and associates them to their semantic characteristics. Derived words and compounds are analysed morphologically; relations between base and derivational form are interpreted semantically (Namer & Baud 2007). The term “morphosemantic” was suggested by Raffaelli & Kerovec (2008) for any work dealing with the relation between form and meaning at the word level.
The resulting morphosemantic formulations notably increase the linguistic and operative competence and performance of FarsNet. This is considered to be an achievement in the codification of the Persian descriptive morphology. The components of the semantic network of nouns can be further obtained by identifying basic concepts of semantic fields and new classifications of semantic categories. However, identifying the lexical gaps between Persian and other languages (e.g. English) can also be helpful in mapping further sections of a wordnet. A practical benefit of such wordnets is that they facilitate human-machine interaction. From a linguistic perspective, they offer new possibilities for semantic analysis.
Data Analysis
An example of analysis is provided by the noun corpus of FarsNet (= 22180 nouns). First of all, the list of derived nouns (= 2756 items) was prepared. Then they were split into their roots and affixes. From the 26 available suffixes, the 12 most frequent ones were selected (= 2461 derivatives). Not surprisingly, their morphological descriptions correspond to Keshani’s (1992) description of Persian suffixes (an example is provided by Table 2).
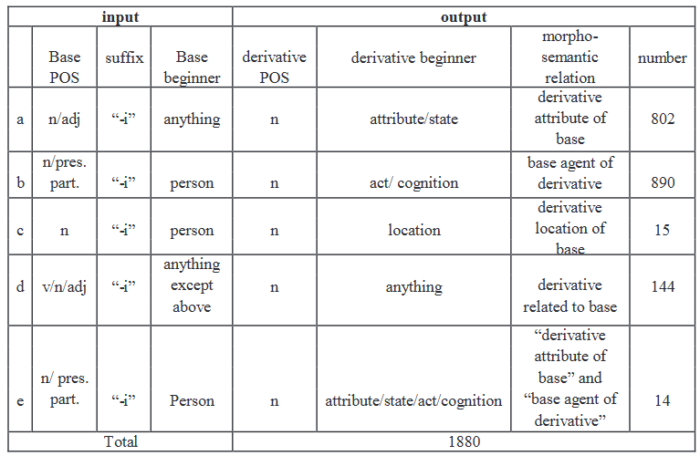
Table 2: Morphological pattern of suffix “-i” derivatives
A morphological analysis of a selection of derived nouns according to semantic categories in FarsNet showed that only 2 words out of 3500 (0.08%) did not fall into the patterns. Thus, it could be concluded that the patterns have successfully provided the foundations for establishing automatic relations between derived or complex nouns and their bases in FarsNet. The consideration of the words’ morphological features such as their PoS, their semantic and grammatical category (e.g. agent noun, participle noun, present participle, etc.) as well as recognizing the beginners of the bases (e.g. act, person, food, etc.) and their change after the affixation process have been the key criteria in formulating the relations which were especially crucial for the majority of studied suffixes that were polysemous. Defining and codifying these morphological patterns lead to a coherent establishment of morphological relations. Hence, this offers a remarkable perspective for the applicability of the data base in machine translation, question answering systems, etc. Although the morphological relations were considered at the word level, mapping the results to the relations formulated in the wordnets of other languages provides a cross-linguistic validity, even if the morphological aspect of the relation is not the same in the two mapped languages.
In my PhD thesis at the Research Center Deutscher Sprachatlas I am transferring these methods to regional varieties of the German language. We expect this to yield new insights into the structuring of the semantics of dialects.
References
- Davari Ardakani, Negar and Mahdiyeh Arvin (2015): Persian. In N. Grandi and L. Kortvelyessy, editors. Edinburgh Handbook of Evaluative Morphology. Edinburgh University Press, Edinburgh, pages 287–295.
- Deléger, Louise, Fiammetta Namer and Pierre Zweigenbaum (2009): Morphosemantic Parsing of Medical Compound Words: Transferring a French Analyzer to English. International Journal of Medical Informatics, 78 (1): 48–55.
- Farshidvard, Khosrow (2007): Derivation and Compounding in Persian. Zavar press, Tehran.
- Keshani, Khosrow (1992): Suffix Derivation in Contemporary Persian. Iran University Press, Tehran.
- Miller, George A. et al. (1990): Introduction to Wordnet. An online Lexical database, Journal of lexicography, 3(4):235–244. doi: 10.1093/ijl/3.4.235
- Raffaelli, Ida and Barbara Kerovec, 2008, Morphosemantic fields in the Analysis of Croatian Vocabulary. Jezikoslovlje, 9 (1–2): 141–169.
- Shamsfard, Mehrnoush et al. (2010): Semi-Automatic Developmen of Farsnet ; The Persian WordNet. 5th Global wordNet conference (GWA8020).
Beitragsbild: Pete Linforth auf Pixabay
Diesen Beitrag zitieren als:
Mirsobhani, Shabnam. 2021. Doing Morphosemantic Analyses in Farsi WordNets. Sprachspuren: Berichte aus dem Deutschen Sprachatlas 1(9). https://doi.org/10.57712/2021-09.