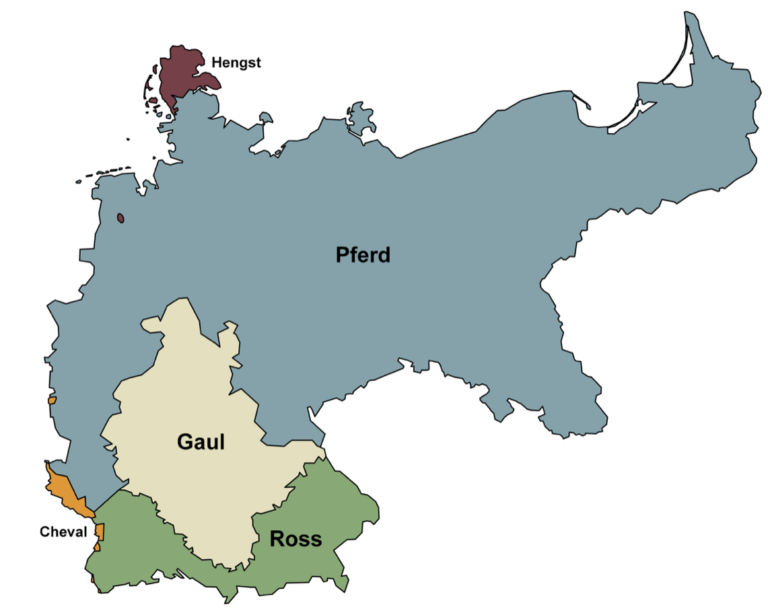
Worin unterscheiden sich die Wörter Pferd, Gaul, Ross, Hengst? „In ihrer Bedeutung“, werden Sie vielleicht denken? Während Pferd die neutrale Bezeichnung für Exemplare der Gattung Equus ist, handelt es sich beim Ross um ein anmutiges Reittier, wohingegen der Gaul seine besten Tage schon hinter sich hat. Hengst wiederum bezeichnet nur das männliche Pferd. So weit, so klar.
Wer einen Blick in die Dialekte des Deutschen wagt, sieht aber sehr schnell, dass die Wörter, die in unserer Standardsprache unterschiedliche Bedeutungen haben, regionalsprachlich Synonyme sind; sie klingen verschieden, meinen aber dasselbe.
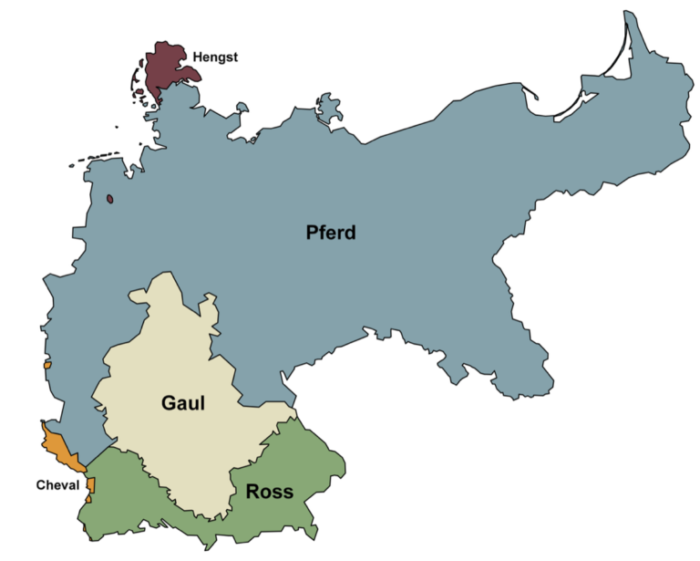
So zeigt die Karte die regionale Verteilung der Ausdrucksvarianten von „Pferd“ in den Dialekten Ende des 19. Jahrhunderts. Das Wort Ross wird vor allem im süddeutschen Raum verwendet, Gaul reicht bis ins Mitteldeutsche hinein. Im nord- und ostdeutschen Raum dominiert das Lexem Pferd und im Friesischen und Dänischen finden wir Formen von Hengst. Anders als in der Standardsprache sind mit den Varianten keine Bedeutungsunterschiede verbunden. Will man also den deutschen Wortschatz in seiner Fülle und Struktur, aber auch in seiner Geschichtlichkeit und Regionalität erfassen, so führt kein Weg an den Dokumentationen und Beschreibungen der Dialekte vorbei.
Am Forschungszentrum Deutscher Sprachatlas (DSA) werden die Dialekte des Deutschen seit 140 Jahren dokumentiert und erforscht. Die Sammlungen umfassen unter anderem mehr als 20.000 Sprachkarten, Sprachaufnahmen aus ca. 6.000 Orten sowie schriftliche Dialektproben aus über 57.000 Orten; darunter viele Dokumente historischer Ortsdialekte, die heute nicht mehr gesprochen werden. Kaum eine andere Sprache auf der Welt ist in ihrer regionalen Vielfalt so gut dokumentiert wie das Deutsche.
Bis in das 20. Jahrhundert hinein waren die Dialekte für die meisten Personen die wichtigste Form gesprochener Sprache. Mit ihrer Vielfalt an Ausdrucksmöglichkeiten spiegeln sie die Kultur- und Mentalitätsgeschichte der ländlichen und städtischen Regionen wider. Auch bilden die Dialekte die Sprachgeschichte ab, Sprachwandel wird im Raum sichtbar. So war Ross das ältere, gemeingermanische Wort, wohingegen Pferd erst im 8. Jahrhundert aus dem mittellateinischen paraveredus entlehnt wurde. Das neue Wort machte schnell Karriere – besonders im fränkischen Westen – und verdrängte von dort ausgehend die älteren Formen im mittel- und norddeutschen Raum, darunter Gaul, das historisch auch im Niederdeutschen verbreitet war.
Die räumliche und historische Komplexität von Wortfeldern ist unserer modernen Standardsprache abhandengekommen. Im Zuge eines langwierigen Ausgleichsprozesses wurden nur Ausschnitte der sprachlichen Vielfalt in die überregionale Schriftsprache aufgenommen. Will man also die deutsche Sprache in ihrer Gesamtheit erfassen, will man einzelne Wortgeschichten nachzeichnen oder auch historische Texte angemessen verstehen können, so sind die dialektalen Wortschätze ein notwendiger Bezugspunkt.
Seit 20 Jahren werden daher die dialektologischen Materialien am DSA digitalisiert. Neben einer langfristigen Sicherung der historischen Quellen liegt das vorrangige Ziel darin, die Forschungsdokumente der Fachcommunity sowie der Öffentlichkeit online verfügbar zu machen. Zu diesem Zweck wurde eine Reihe von Online-Anwendungen entwickelt, über die auf die Dokumente zugegriffen werden kann. Zentral ist dabei das sprachgeographische Informationssystem SprachGIS, in dem über eine Kartenansicht digitalisierte Sprachkarten betrachtet werden können. Die Sprachkarten sind mit zahlreichen Sprachaufnahmen, ortsbezogenen Literaturangaben sowie weiteren Datensätzen verknüpft. Auch lassen sich neue Datensätze in das System integrieren und eigene Karten zeichnen.
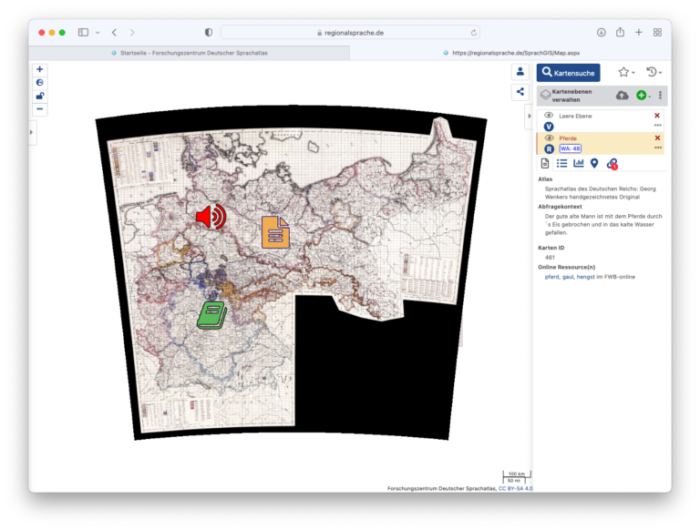
Das SprachGIS, das im Rahmen des Akademieprojekts Regionalsprache.de (REDE) entwickelt wurde, stellt damit ein interaktives Forschungswerkzeug dar, mit dem die Nutzer:innen verschiedene Datenbestände systematisch aufeinander beziehen und analysieren können. Auf diesem Weg lässt sich der tiefgreifende Wandel von den historischen Dialekten zu den modernen Regionalsprachen, der die Entwicklungen des 20. Jahrhunderts kennzeichnet, detailliert nachzeichnen. Die Dialektdaten sind jedoch nicht nur innerhalb der Marburger Web-Anwendungen miteinander vernetzt, sondern sie sind auch mit anderen sprachwissenschaftlichen Online-Portalen verbunden, zum Beispiel mit dem Trierer Wörterbuchnetz und dem Göttinger Frühneuhochdeutschen Wörterbuch.
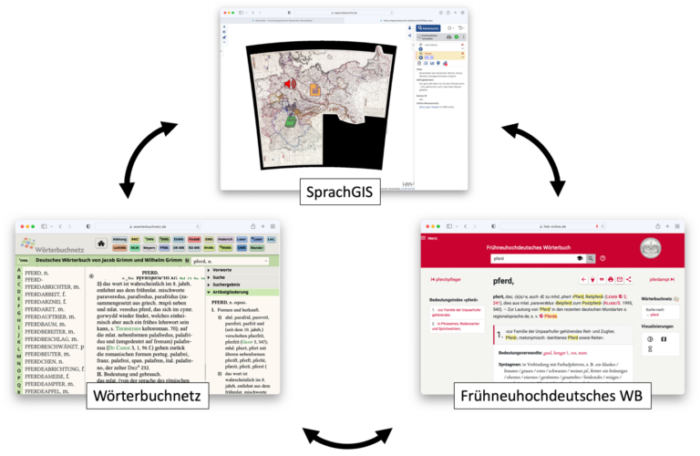
Die sprachlichen Forschungsdaten sind damit nicht mehr auf ihren Publikationsort – zum Beispiel eine Dialektkarte oder ein Wörterbuchartikel – beschränkt, sie überschreiten räumliche und mediale Grenzen. Sie werden Teil eines „digital entgrenzten Wissensraums“ (Ceynowa 2014, siehe auch Lameli 2018). In diesem Wissensraum werden die dialektalen Daten Bestandteil einer allgemeinen Kulturgeschichte.
Diesen digitalen Wissensraum noch einmal wesentlich zu erweitern, ist Ziel der gemeinsamen Bemühungen in der Task Area Lexikalische Ressourcen des NFDI-Konsortiums Text+. Als Linked Open Data werden die dialektalen Forschungsdaten mit denen zahlreicher anderer Ressourcen dynamisch verbunden. In Zusammenarbeit verschiedener Partner wird ein gemeinsames Rechercheportal entwickelt, das eine vernetzte Suche sowie eine Vielzahl automatisierter Abfragen und Analysen ermöglicht. Für die Öffentlichkeit, für Schulen, aber auch für Forschende verschiedenster Disziplinen wird damit der digitale Wissensraum der Sprache über ein zentrales Portal erkundbar: über eine föderierte Suchmaschine für Sprache. Zugleich entsteht über das Konsortium Text+ ein Kooperationsverbund, der neue technische Maßstäbe für die Vernetzung sprachlicher Daten und den Aufbau von Forschungsdateninfrastrukturen setzen wird.
Mit den einmaligen Beständen an digitalen Dialektdaten und der langjährigen Expertise in der Entwicklung von Online-Informationssystemen trägt das Forschungszentrum Deutscher Sprachatlas seinen Teil zum Gelingen dieses Vorhabens bei.
Literatur:
Ceynowa, Klaus (2014): Digitale Wissenswelten – Herausforderungen für die Bibliothek der Zukunft. In: Zeitschrift für Bibliothekswesen und Bibliographie 61(4/5), S. 235–238. http://dx.doi.org/10.3196/18642950146145109.
Lameli, Alfred (2018): Alte Karten, neue Daten. Zur Transformation eines historischen Grundlagenwerks der Sprachwissenschaft. In: Zeitschrift für Bibliothekswesen und Bibliographie 65(5–6), S. 259–267. http://dx.doi.org/10.3196/1864295018655635.
Anmerkung
Dieser Text wurde ursprünglich hier veröffentlicht: Ressourcen-Reigen, #1: Deutscher Sprachatlas. Dialekte im digitalen Wissensraum der Sprache – Text+ Blog (hypotheses.org)
Diesen Beitrag zitieren als:
Fischer, Hanna. 2023. Dialekte im digitalen Wissensraum der Sprache. In: Sprachspuren: Berichte aus dem Deutschen Sprachatlas 3(3). https://doi.org/10.57712/2023-03