In der Dialektforschung wurde die Syntax, wie jüngst in einem Sprachspuren-Beitrag von Hanna Fischer, Simon Kasper und Jeffrey Pheiff (2022) aufgezeigt wurde, lange Zeit vernachlässigt, unter anderem, weil man nicht glaubte, dass sprachgeographisch relevante Unterschiede in syntaktischer Hinsicht überhaupt existieren. Diese Ansicht kann heute als unbegründet zurückgewiesen werden, wie man etwa anhand der Dialekte, die im Bundesland Hessen gesprochen werden, zeigen kann.
Das Projekt Syntax Hessischer Dialekte (SyHD)
Im Projekt „Syntax hessischer Dialekte“ (SyHD, 2010–2016) wurden im gesamten Bundesland Hessen verschiedene syntaktische Strukturen per Fragebogen (bei über 700 Personen) bzw. in direkten Interviews (bei über 150 Personen) systematisch erhoben und ausgewertet. Die Gewährspersonen waren zum Zeitpunkt der Fragebogen und Interviews durchschnittlich über 70 Jahre alt und sie wohnten in Ortschaften von ca. 500‑1500 Personen. Sie zeigen damit also einen Sprachstand, wie er heute bei den jüngeren Generationen in vielen Gebieten nicht mehr vorhanden sein dürfte und den man in der Mundartforschung als „basisdialektal“ bezeichnet. Aus der Befragung ist unter anderem SyHD-atlas entstanden (Fleischer et al. 2017). Dort sind die Resultate des Projekts in elektronischer Form publiziert.
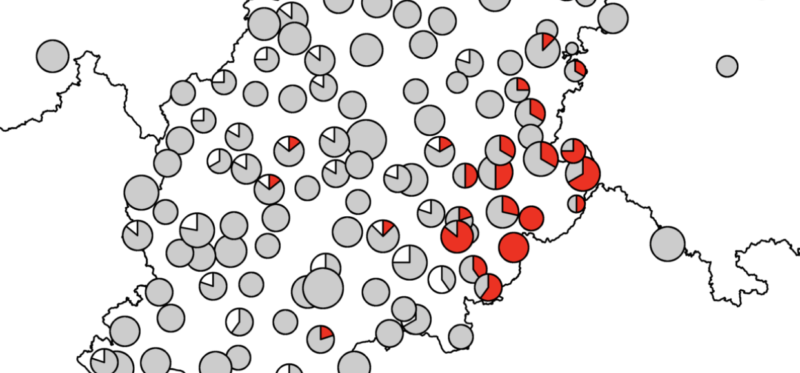
Im SyHD-Projekt hat sich gezeigt, dass sich die im Bundesland Hessen gesprochenen Dialekte in syntaktischer Hinsicht nicht nur von der Standardsprache, sondern auch voneinander deutlich unterscheiden. So wird etwa in den Mundarten Osthessens eine gegenüber der Standardsprache „umgedrehte“ Abfolge von Hilfsverb und Hauptverb verwendet: Hier ist die Abfolge ich weiß nicht, ob er einmal will heiraten, die auch in älteren Formen des Deutschen verbreitet war, möglich (s. Karte 1). Auf dieser Karte entspricht die Größe der Symbole der Anzahl der für den jeweiligen Ort sinnvoll beantworteten Fragen. Je größer der Kreis, umso mehr Antworten liegen also vor. Es zeigt sich sehr deutlich, dass die „umgedrehte“ Abfolge, die mit Rot symbolisiert wird, fast ausschließlich im Südosten des Bundeslandes, im Osthessischen, verbreitet ist.

Aggregierung syntaktischer Daten
Im Rahmen des SyHD-Projekts wurden über hundert derartige Karten erarbeitet. Es ist darum gar nicht einfach, sich einen Überblick über die einzelnen syntaktischen Phänomene hinaus zu verschaffen. An dieser Stelle hilft eine relativ junge Teildisziplin der Mundartforschung: die Dialektometrie. In der Dialektometrie werden Dialektdaten quantifiziert und aggregiert, um z.B. Aussagen über die Ähnlichkeit von Dialekten zu machen. Beim SyHD-Projekt kann man aus über hundert Dialektkarten zu unterschiedlichen Phänomenen eine einzige Karte ableiten, die die wichtigsten Differenzierungen aufzeigt. Dabei ergibt sich ein interessantes Resultat, das in der folgenden Karte mit einem in der Dialektometrie üblichen Verfahren visualisiert ist. Um die Resultate in einer Fläche darzustellen, wurde um jeden dokumentierten Ortspunkt ein Polygon gezogen. Die Farbtöne in Karte 2 zeigen auf, welche Orte einander syntaktisch besonders ähnlich oder unähnlich sind: je ähnlicher die Farbe, umso ähnlicher die syntaktischen Strukturen.
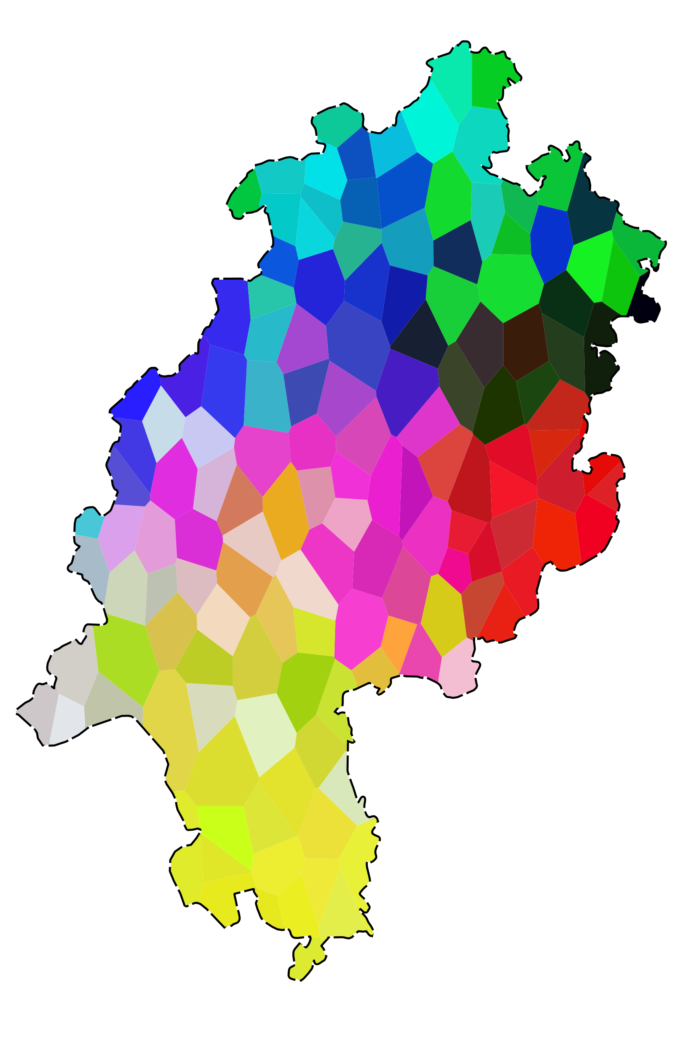
Für die Syntax der in Hessen gesprochenen Dialekte zeigen sich also deutliche areale Schwerpunkte. Beispielsweise tritt das Osthessische, das bei der „umgedrehten“ Abfolge der Verben bereits in Erscheinung getreten ist, klar hervor (in roter Farbe in Karte 2). Die lange verbreitete Vorstellung, dass syntaktische Strukturen keine arealen Unterschiede aufweisen, wird durch dieses Ergebnis – wie auch durch viele Karten zu Einzelphänomenen – also ein weiteres Mal falsifiziert. Allerdings scheinen die Grenzen bei genauerer Betrachtung nicht ganz so klar zu sein, wie man dies aus anderen Dialektkarten kennt: So finden sich ähnliche Farbtöne zum Teil etwas weiter voneinander entfernt, unterbrochen durch etwas weniger ähnliche Farben, gerade etwa im Norden von Hessen, wo Grün- und Blautöne einander häufig abwechseln.
Traditionelle Einteilung
Die traditionellen Einteilungen der deutschen Dialekte beziehen sich in der Regel auf lautliche Unterschiede. Am bekanntesten ist die Klassifikation anhand der Ergebnisse der Zweiten Lautverschiebung, d.h. anhand der Entwicklung der germanischen Plosive p, t und k: Anhand dieses Kriteriums werden die niederdeutschen Dialekte (Zweite Lautverschiebung wurde nicht durchgeführt, etwa Tid, Water, maken, schlapen) von den hochdeutschen (Zweite Lautverschiebung durchgeführt, etwa Zeit, Wasser, machen, schlafen) unterschieden. Bei vielen Wörtern mit einem germanischen Plosiv zeigt sich der exakt gleiche areale Verlauf, der so klar ist, dass er als eine Linie dargestellt werden kann. Als „Benrather Linie“ (nach Benrath, einem Vorort von Düsseldorf, wo diese Grenze im Westen verläuft) ist die Abgrenzung zwischen Niederdeutsch und Hochdeutsch auch allgemein bekannt geworden. Für feinere Unterteilungen werden – in der heute am weitesten verbreiteten Einteilung von Peter Wiesinger – neben der zweiten Lautverschiebung auch vokalische Entwicklungen herangezogen.
Für die Dialekte Hessens zeigt die folgende Darstellung in Karte 3, welche Dialekte verbreitet sind. Hier werden die Grenzen des Bundeslands auf einen Ausschnitt aus der Dialekteinteilungskarte projiziert. Es zeigt sich, dass im Norden Hessens niederdeutsche (westfälische und ostfälische) Dialekte gesprochen werden, im Zentrum mit dem Nordhessischen, Zentralhessischen und Osthessischen dann die „eigentlichen“ hessischen Dialekte, im Süden ist das Rheinfränkische verbreitet. Auf dieser Karte ist die „Benrather Linie“ die Linie, die das West- und Ostfälische vom Nordhessischen trennt.
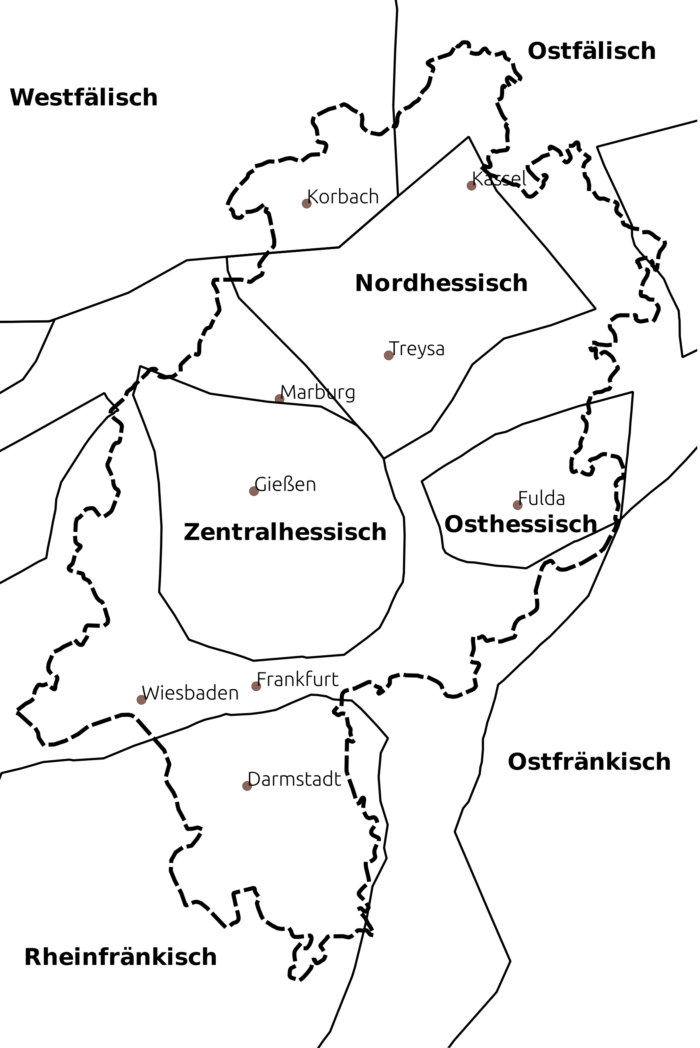
Wenn man die traditionelle, vor allem auf lautlichen Phänomenen beruhende Dialekteinteilung mit der aufgrund der syntaktischen Ähnlichkeit erstellten Karte 2 vergleicht, zeigt sich, dass sich die Benrather Linie bei den syntaktischen Daten gar nicht wiederfindet. In Bezug auf das Osthessische zeigen dagegen beide Karten ähnliche Bilder.
Neue Analyse der lautlichen Unterschiede
Entspricht nun aber Karte 3, die sich im Wesentlichen auf Daten des 19. und frühen 20. Jahrhunderts stützt, auch noch dem aktuellen Stand? Die SyHD-Daten waren auf syntaktische Strukturen ausgerichtet und lassen somit keine direkte Antwort auf diese Frage erwarten. Allerdings kann durch eine „Sekundärauswertung“ auch die lautliche Ebene erstaunlich klar erfasst werden. Während die Mehrzahl der SyHD-Fragen durch einfaches Ankreuzen beantwortet werden konnte, wurden insgesamt sieben Mal auch ganze Sätze aus der Standardsprache in den jeweiligen Dialekt übersetzt. Das folgende Beispiel zeigt dies für den Satz „Früher wohnten wir hinter der Kirche, aber dann bauten wir noch mal neben der Schule.“ In Ulrichstein wurde dieser Satz etwa folgendermaßen übersetzt (1). Schon in diesen wenigen Wörter zeigen sich zahlreiche lautliche Merkmale des lokalen Dialekts, etwa bei der charakteristischen Form hu ‘haben’ oder beim Ausfall von -e in Schul.
(1) Erst hu merr hinner de Kirch gewuhnt un dann hu merr bei die Schul nau gebaut.
Wie kann man nun aber derartige Übersetzungen in lautlicher Hinsicht miteinander vergleichen? An dieser Stelle kommt ein in der Dialektologie bisher wenig verwendetes Verfahren ins Spiel, die sog. n-Gramm-Analyse. n-Gramme sind Abfolgen von n linguistischen Einheiten wie Buchstaben, Wörter o.ä. Bei Sequenzen aus einem Buchstaben spricht man von Unigrammen, bei solchen aus zweien von Bigrammen und bei Sequenzen aus drei Buchstaben von Trigrammen. Wenn man aus einem Text – beispielsweise aus Über allen Gipfeln ist Ruh – Buchstaben-n-Gramme erstellt, sieht das so aus:
| Unigramm | Bigramm | Trigramm |
| Ü,b,e,r, ‚a,l,l,e,n, ‚G,i,p,f,e,l,n, ‚i,s,t, ‚r,u,h | Üb,be,er,r , a,al,ll,le,en,n , G,Gi,ip,pf,fe,el, ln,n , i,is,st,t , r,ru,uh | Übe,ber,er ‚r a, al,all,lle,len,en ‚n G, Gi,Gip,ipf,pfe, fel,eln,ln ‚n i, is,ist,st ‚t r, ru,ruh |
Solche Abfolgen lassen sich mithilfe des Computers einfach erstellen und auszählen. So verschafft man sich schnell ein Bild über häufige Buchstabenkombinationen. Frequenzen solcher Buchstabenkombinationen können zwischen Dialekten verglichen werden. Idealerweise bezieht man sich dabei auf den gleichen Ausgangstext oder auf eine größere Materialmenge, da sonst die Vergleichbarkeit nicht gewährleistet ist. Wenn Ähnlichkeiten solcher Buchstabenkombinationen – hier werden Trigramme verwendet – zwischen einzelnen Orten mit dem gleichen Verfahren wie die syntaktischen Ähnlichkeiten errechnet werden, ergibt sich folgendes Resultat (s. Karte 4).
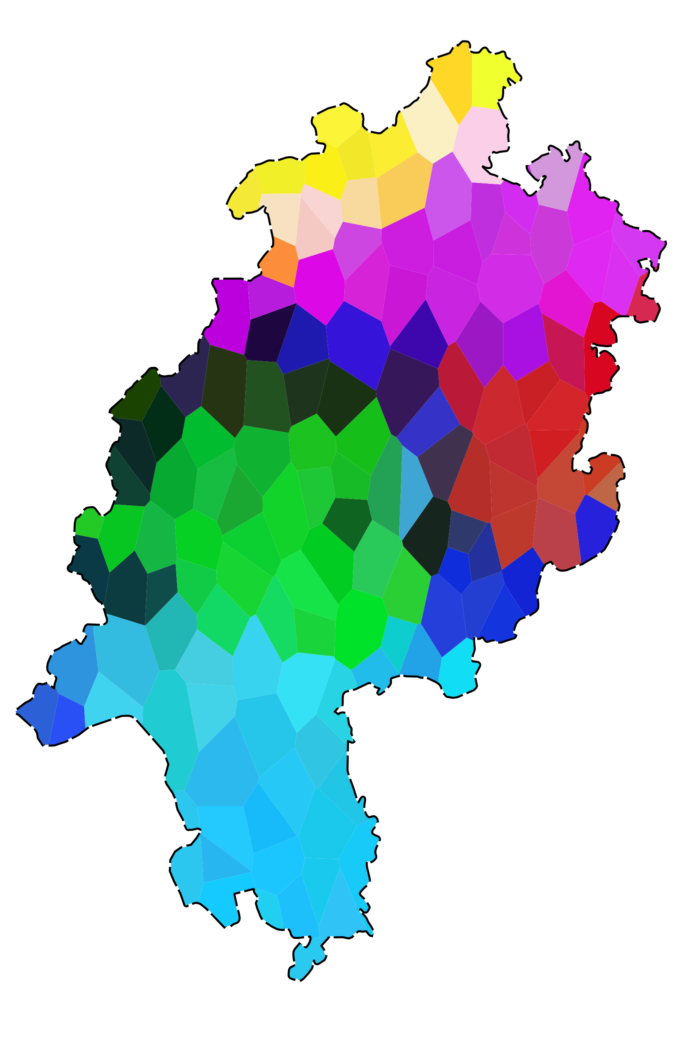
In dieser Karte zeigen sich die traditionellen Dialekträume in fast genau der Art und Weise wie in der traditionellen Dialekteinteilungskarte! Die niederdeutschen Dialekte (ohne zweite Lautverschiebung) erscheinen gelb, das Nordhessische violett, das Zentralhessische grün, das Osthessische rot und das Rheinfränkische blau. Interessant sind auch die Übergangsbereiche zwischen den Kernräumen, etwa die Schwalm, die zwischen den verschiedenen Räumen steht. Auch in den traditionellen Dialekteinteilungen ist gerade diese Landschaft häufig nicht eindeutig verortet.
Syntax ist anders
Das Interessante an diesen Daten ist, dass sich auch zu Beginn des 21. Jahrhunderts die bekannten dialektalen Räume finden lassen. Aus diesem Vergleich ergibt sich übrigens auch eine schöne Validierung des im frühen 21. Jahrhundert erhobenen SyHD-Materials. In qualitativer Hinsicht finden sich allerdings in den Trigramm-Daten viel deutlichere Räume als bei den Syntax-Daten. Weil beide Datensätze aus dem gleichen Fundus stammen (sie wurden bei den gleichen Personen zum gleichen Zeitpunkt erhoben), kann dieser Unterschied nicht durch die Methode oder den Zeitpunkt der Erhebung bedingt sein. Somit lässt sich festhalten: Auch syntaktische Phänomene weisen deutliche areale Strukturen auf – aber diese areale Strukturierung ist doch in einer charakteristischen Weise anders als die der lautlichen Räume.
Interessanterweise lassen sich nun bei den syntaktischen Daten in Hessen Niederdeutsch und das angrenzende Hochdeutsche nicht voneinander unterscheiden – die Benrather Linie ist also in Hessen keine syntaktische Grenze! Ob sich die syntaktischen räumlichen Muster in ähnlicher Weise auch bei anderen sprachlichen Phänomenen – etwa dem Wortschatz – oder vielleicht sogar in außersprachlichen Entsprechungen wiederfinden, ist eine spannende Frage für die zukünftige Forschung.
Die hier vorgestellten Resultate beruhen auf dem frei verfügbaren Aufsatz von Birkenes & Fleischer (2021). Daraus stammen die hier wiedergegebenen Karten und darin wird die verwendete Methode genauer beschrieben.
Literatur
Birkenes, Magnus Breder & Jürg Fleischer. 2021. Syntactic vs. phonological areas: A quantitative perspective on Hessian dialects. Journal of Linguistic Geography 9: 142–161. https://doi.org/10.1017/jlg.2021.9
Fischer, Hanna, Simon Kasper & Jeffrey Pheiff. 2022. Wenn Thomas “größer wie” sein Bruder ist. Regionale Variation im Satzbau. Sprachspuren: Berichte aus dem Deutschen Sprachatlas 2(3). https://doi.org/10.57712/2022-03.
Fleischer, Jürg, Alexandra N. Lenz & Helmut Weiß. 2017. SyHD-atlas. Konzipiert von Ludwig M. Breuer. Unter Mitarbeit von Katrin Kuhmichel, Stephanie Leser-Cronau, Johanna Schwalm und Thomas Strobel. Marburg/Wien/Frankfurt am Main. https://doi.org/10.17192/es2017.0003
Diesen Beitrag zitieren als:
Birkenes, Magnus Breder & Jürg Fleischer. 2022. Die Benrather Linie ist keine syntaktische Grenze! Sprachspuren: Berichte aus dem Deutschen Sprachatlas 2(9). https://doi.org/10.57712/2022-09.