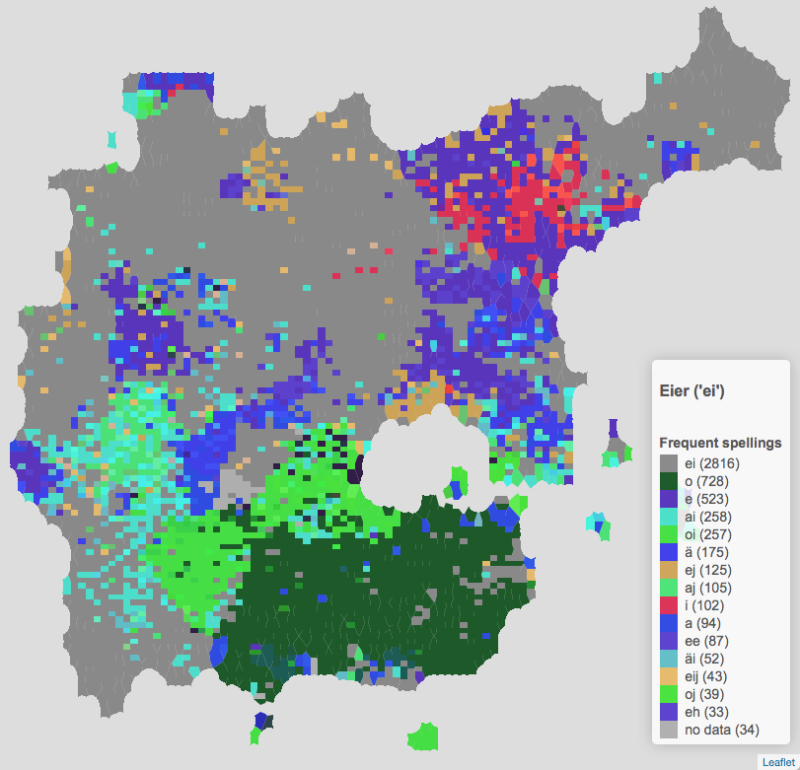
Die handgezeichneten Karten des „Sprachatlas des Deutschen Reichs“ (Wenkerkarten) sind ein eindrucksvolles Resultat einer enormen Datenerhebung und eines detaillierten manuellen Kartierungsverfahrens. Ich will hier einen Versuch einer zeitgemäßen Visualisierung vorstellen, die genauso detailgetreu und zugleich intuitiv leichter verständlich ist als Wenkers Originalkarten. Das zentrale Problem besteht dabei darin, alle einzelnen Formen eines Erhebungsphänomens zu repräsentieren, ohne die Karte unübersichtlich werden zu lassen. Vor allem bei der Kartierung der Vielfalt an vokalischen Varianten ist das eine große Herausforderung.
Verschiedene Kartierungsversuche
Georg Wenker (s. Sprachspuren 2021-11) hat seine Daten mittels Fragebögen erfasst, die von lokalen Schullehrern ausgefüllt wurden. In ihrem Versuch, die lokale Aussprache zu charakterisieren, haben die Lehrer dabei die ihnen bekannten orthographischen Mittel der deutschen Rechtschreibung benutzt (wie Dehnungs-h oder Umlaut). Dadurch liegen die Daten in einer jeweils individuellen und damit uneinheitlichen Verschriftlichung vor. Eine der zentralen Ansichten Georg Wenkers war, dass sich aus diesen Laien-Transkriptionen dennoch sehr gute Raumbilder der sprachlichen Vielfalt der deutschen Dialekte darstellen lassen.
Wenkers Prinzip der Kartierung war, die Sprachformen genauso in den Karten abzubilden wie sie von den Lehrern aufgeschrieben worden waren. Um die Bilder nicht mit Informationen zu überfrachten, hat er sog. Leitformen benutzt. Innerhalb der Grenzen einer farblich markierten Leitform wird ein Auftreten dieser Form nicht mehr explizit kartiert. Nur die Formen, die nicht zur Leitform gehören, werden eingezeichnet. Die Entscheidungen über den Grenzverlauf dieser Leitformen und der sie umgebenden Isoglossen sind dadurch natürlich von sehr großem Einfluss auf den visuellen Eindruck einer Karte. Graduelle Übergänge oder Gebiete mit einer Mischung verschiedener Sprachformen sind nicht oder nur schwer visuell erkennbar.
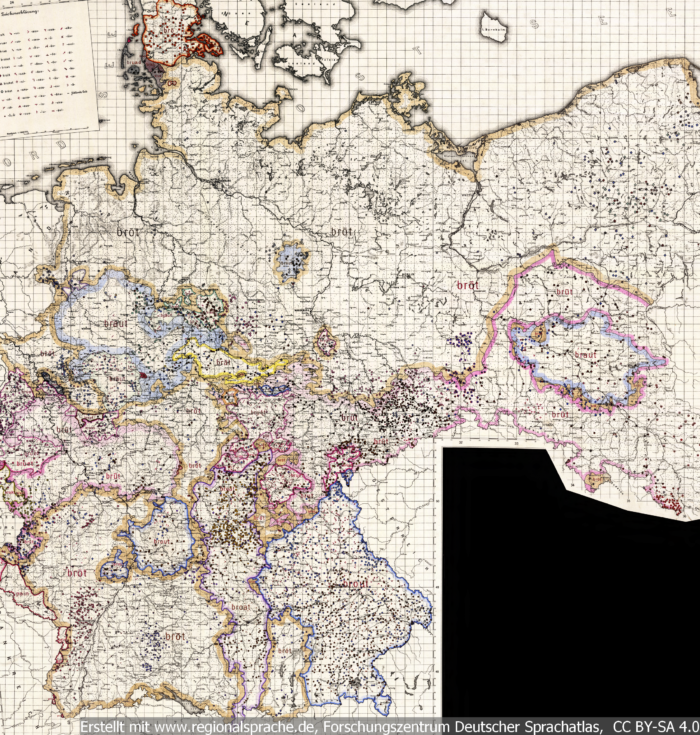
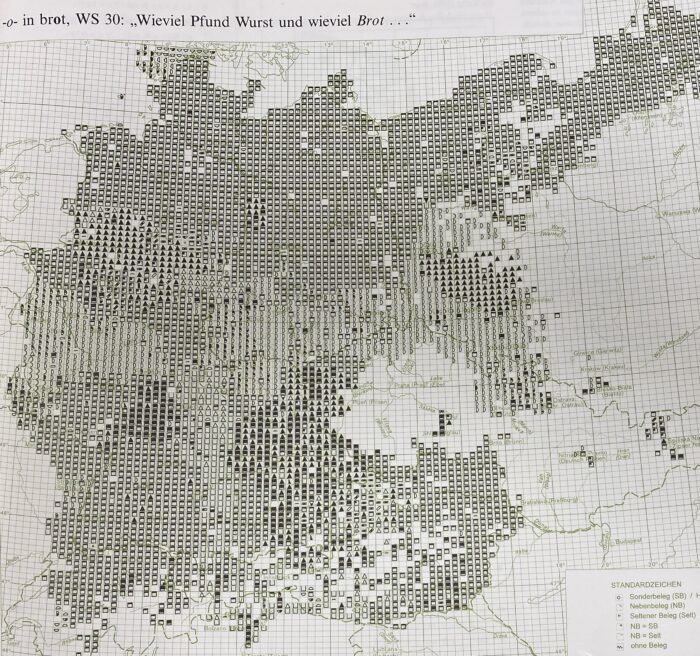
Auch mehr als 100 Jahre nach Wenkers Erhebungen liegen noch immer nur Bruchteile der Daten in transliterierter und damit elektronischer Form vor. Für diesen Artikel verwende ich die Transliterationen der Wenkerbögen, die im Rahmen des „Kleinen Deutschen Sprachatlas“ (KDSA) angefertigt worden sind. Für diesen Atlas wurden fast 6.000 Wenkerbögen ausgewählt. Einzelne Formen aus diesen Bögen wurden transliteriert und elektronisch erfasst. Auf Basis dieser Daten ist der KDSA als ein klassischer gedruckter Atlas entstanden.
Die Darstellung im KDSA ist leider nicht sehr intuitiv erfassbar. Gemäß der Tradition des Ursprungsmaterials hat in diesem Atlas jede einzelne Sprachform ein eigenes Symbol. Aber in Karten mit vielen verschiedenen Sprachformen werden dadurch viele Dutzend verschiedene Symbole benutzt, was visuell ein eher konfuses Bild der geographischen Verteilung ergibt. Vor allem fehlt das Wenker’sche Prinzip der Leitform als visuelle Vereinfachung.
In meinem Vorschlag zur Kartierung benutze ich Farben, um die verschiedenen Sprachformen darzustellen. Dabei erhält jede Sprachform eine eigene Farbe. Wenn nur ein paar Sprachformen vorkommen (wie bei den meisten Karten zu konsonantischen Phänomenen), dann können diese Formen einfach mit wenigen klar unterscheidbaren Farben wiedergegeben werden. Grenzen sind dann nicht mehr notwendig und Übergänge oder Mischgebiete sind direkt zu erkennen.
Wenn aber mehrere Dutzend Sprachformen abgebildet werden müssen (wie bei den meisten Karten zu vokalischen Phänomenen), dann braucht es eine zusätzliche Technik um die zahlreichen notwendigen Farben zu wählen. Das Prinzip, das ich verwende, ist intuitiv und einfach: Ähnliche Vokale sollen mit ähnlichen Farben dargestellt werden. Das farbliche Kontinuum wird so benutzt, um den kontinuierlichen Vokalraum abzubilden. Dadurch lassen sich plötzliche Farbübergänge im Raumbild als starke Sprachgrenzen interpretieren, während gemischte Gebiete und kontinuierliche Übergänge ebenso einfach zu erkennen sind.
Prinzipien der Kartierung
Bei der Gestaltung der Karten habe ich folgende Prinzipien zu Grunde gelegt. Sie werden im Folgendem etwas ausführlicher besprochen. Mehrere Beispiele stehen online zur Verfügung.
- Jede geschriebene Originalform aus den Erhebungsbogen wird direkt kartiert. Farben werden benutzt, um eine visuelle Interpretation zu erleichtern.
- Ähnliche Farben werden für ähnliche Sprachformen benutzt, wobei die Schreibweise aus der Vorgabe (Wortlaut der hochdeutschen Wenkersätze in orthographisch korrekter Schreibweise) immer grau dargestellt wird.
- Die Darstellung füllt den gesamten geographischen Raum: Die gesammelten Daten werden als eine Stichprobe interpretiert, die repräsentativ sein sollte für den gesamten Raum.
Dem Prinzip von Wenker folgend werden die Daten nicht vereinfacht oder umgedeutet, um eine Kartierung zu ermöglichen, sondern sie werden direkt so kartiert, wie sie in den handschriftlichen Bögen stehen. Jede einzelne Form ist in jeder Karte dargestellt. Um die Karten nicht mit Informationen zu überfrachten, sind die Sprachformen elektronisch hinterlegt. Sie lassen sich durch einen Klick auf die Karte aufrufen (im Moment liegen leider noch keine Informationen zu den Orten und Bogennummern elektronisch vor, aber sie sollen zukünftig auch hinzugefügt werden).
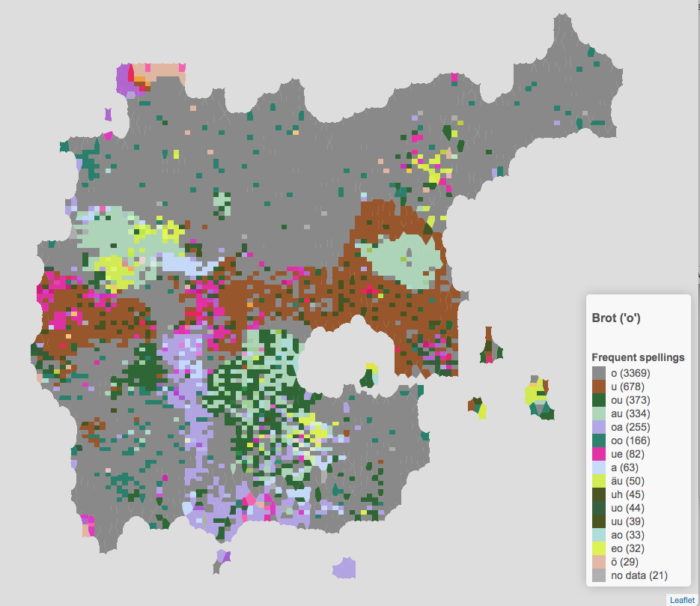
Jede Sprachform hat eine eigene Farbe auf der Karte. Die Details der Farbgebung in der jetzigen Fassung der Karten ist sicher nicht immer ideal, aber solche ästhetischen Einwände sind technisch leicht lösbar. Die Farbe Grau wird immer benutzt, um die Form der deutschen Orthographie darzustellen. Zum Beispiel in der vorherigen Karte Brot ist deshalb das Vorkommen des <o> grau. Hellgrau wird benutzt für fehlende Daten und manchmal auch für Formen, die nur ein oder zweimal vorkommen (durch klicken kann die Originalform immer herausgefunden werden). Bei bis zu maximal einem Dutzend verschiedenen Formen werden alle Varianten in der Legende aufgelistet. Bei den Vokalen (mit oft bis zu 100 verschiedenen Formen) wird aber nur eine Auswahl der häufigsten Varianten in der Legende gezeigt.
Die Farben füllen den gesamten Raum des Erhebungsgebiets. Es gibt eine Lücke im tschechischen Sprachraum sowie bei einigen Sprachinseln im Süden und Osten. Darüber hinaus gibt es keine weißen Flächen in den Karten. Obwohl natürlich nur einzelne Datenpunkte erhoben worden sind, habe ich mich trotzdem dafür entschieden den gesamten Raum zu füllen, anstatt voneinander getrennte Symbole zu benutzen. Diese Entscheidung habe ich einerseits getroffen, um den visuellen Eindruck zu verbessern. Anderseits hat dies auch einen theoretischen Hintergrund: Wenn die erhobenen Daten die wirkliche Sprachvielfalt erfassen, dann sind die Daten eine repräsentative Stichprobe. Wenn sie das nicht wären, dann wäre gar keine dialektologische Schlussfolgerung möglich und jegliches Kartieren überflüssig. Zwar steht jeder Farbtupfer noch immer für einen Datenpunkt, aber die Gebiete zwischen zwei benachbarten Datenpunkte werden jetzt ausgefüllt.
Die Farbtupfer auf der Karte sehen quadratisch aus und in vielen Fällen sind sie das auch. Das ist aber kein Grundsatz der Visualisierung, sondern der Datensammlung des KDSA geschuldet. In der Planung des KDSA sind die 6.000 Bogen anhand eines Koordinatengitters ausgewählt worden. Die vorhandenen Daten sind deshalb sehr regelmäßig über den geographischen Raum verteilt und das Ausfüllen des kompletten Raumes verursacht dadurch fast überall quadratische Polygone. Bei genauer Betrachtung der Karte lässt sich aber feststellen, dass nicht alle Farbtupfen quadratisch sind (z. B. in manchen Ecken des Sprachraumes). Die Form der Polygone ist aber nicht bedeutungstragend.
Das Problem der Vokale
Die Kartierung von Konsonanten stellt keine großen Probleme dar. Die Menge an Varianten ist relativ klein und es kommen nur eine Handvoll Varianten häufig vor. Ein paar wenige Farben reichen deshalb aus, um ein gutes Raumbild zu erstellen. Bei Vokalen ist die Situation aber komplett anders. Zum Beispiel der Vokal <o> in Brot hat 92 verschiedene Verschriftlichungen in den KDSA-Daten, siehe (1). Hier braucht es also 92 verschiedene Farben für die Karte.
| (1) | Verschiedene Verschriftlichungen von <o> in Brot: |
| a, ä, aa, äa, aae, aao, aau, äau, ääu, ae, äeu, ah, ai, aie, ao, äo, aou, äou, ar, au, aü, äu, äü, auo, auu, e, ea, eao, eäu, ee, ei, eju, eo, eoa, eoo, eou, eroi, eruh, eu, eü, iäu, o, ö, oa, oä, öä, oaa, oao, oau, öau, oe, öe, oh, öh, oi, oo, öo, öö, ooa, ooä, ooe, ooi, ooo, oou, oouu, ou, oü, öu, oua, oue, ouu, ow, u, ü, ua, uä, uar, uau, ue, uee, uer, uh, uhe, ui, uo, uö, uoe, ur, uu, üü, uue, uui, |
Um die Farben für alle 92 Formen auszuwählen, habe ich eine Technik benutzt, die ursprünglich von Wilbert Heeringa (2004) in einem anderen Kontext vorschlagen wurde. In einem ersten Schritt wird jeder Vokal als eine Reihe von 12 Zahlen charakterisiert. Die ersten fünf Zahlen beschreiben die Veränderung der Vokalhöhe (in vier groben Stufen) und die nächsten fünf Zahlen beschreiben die Kontur der Vokalposition (in 6 groben Stufen). Die letzten beiden Zahlen stehen für die Wiedergabe der Länge. All diese Zahlen basieren nur auf den Verschriftlichungen in den Bögen und sind deshalb phonetisch sehr ungenau. Sie erfüllen aber den Zweck, die Farben für die Visualisierung zu bestimmen.
Diese Zahlenreihen lassen sich in einem zweiten Schritt mittels einer Metrik (z. B. euklidische Distanz) einfach mathematisch vergleichen. Daraus entsteht dann eine Distanzmatrix mit berechneten Distanzen für jedes Vokalpaar. Solch eine Distanzmatrix lässt sich mittels eines Verfahrens der sog. Dimensionsreduktion bearbeiten, z. B. Multidimensionale Skalierung. Das Resultat ist, dass jeder Vokal Koordinaten im dreidimensionalen Raum zugewiesen bekommt. Dieser Raum ist nicht für die Kartierung gedacht, sondern die drei Koordinaten werden benutzt, um eine RGB-Farbe (Rot-Grün-Blau) zu bestimmen. Diese Farbe wird dann in der Karte eingetragen. Die Farben werden momentan für jede Karte neu bestimmt auf Basis des Vorkommens der Varianten. Deshalb sind die Farben (noch) nicht über die Karten hinweg vergleichbar.
Der Effekt dieser Technik ist erstaunlich gut und das Resultat stimmt in vielen Facetten mit den originalen Wenkerkarten überein. Im Vergleich zum Original sind aber noch bessere Einschätzungen zur Klarheit der Grenzen und zu Übergangs- und Mischgebieten möglich. Zum Beispiel kommt die Schreibung <au> in der Karte von Brot (hellgrün) in drei Arealen vor, aber jeweils auf ein andere Art (die Karte wird unten nochmal dargestellt). Die Karte zeigt eine ganz klare Grenze zwischen der Ausbreitung von <u> (braun in der Mitte der Karte) und die Region mit <au> in Schlesien (hellgrün im Osten das braunen Gebietes). Ein Areal mit <au> im Westen (hellgrün) ist auch gut erkennbar, aber hier gibt es Übergangsvarianten mit ähnlichen Farben (Gelbtöne für ähnliche Diphthonge wie <äu>, <eo> und <äeu>, hellviolett für <a>). In Bayern ist eine Region mit einer Mischung von <au> (hellgrün) und <ou> (dunkelgrün) zu erkennen. Obwohl in allen drei Gebieten typisch <au> vorkommt, scheint der Kontext jeweils ein anderer zu sein.
Webtechnologie
Technisch gesehen basieren die Karten in diesem Aufsatz auf weitverbreiteten Webtechnologien (HTML, CSS & Javascript). Obwohl die Karten dadurch online angeschaut werden können, ist es wichtig zu verstehen, dass das Internet für die Darstellung nicht notwendig ist. Eine Karte ist immer eine einzelne selbständige Datei, die einfach gespeichert und geteilt werden kann. Man kann sie zum Beispiel problemlos in einer E‑Mail oder in einer anderen elektronischen Kommunikationsform verschicken. Die Darstellung der Karte erfolgt immer über einen Webbrowser (Chrome, Firefox, Safari usw.), auch wenn die Datei lokal auf einem Rechner liegt und der Rechner nicht mit dem Internet verbunden ist.
Wenn Sie zum Beispiel diese Karte online aufrufen, dann können Sie über die Funktion des Webbrowsers die Karte lokal auf Ihrem Rechner speichern („speichern unter …“) als HTML-Quellcode. Sie haben dann eine Datei mit der Endung „.html“, die Sie wie jede andere Datei benutzen können. Ein Doppelklick auf die Datei öffnet die Karte im Webbrowser. Wenn Sie aber genau nach der Internetadresse im Browser schauen, dann werden Sie sehen, dass diese Webseite lokal auf Ihrem Rechner liegt (die Adresse fängt an mit „file://“).
Die Karten wurden erstellt in R https://www.r-project.org und der Javascript-Bibliothek leaflet https://leafletjs.com. Die Fortschritte des Projektes zur neuen Internet-basierten Analyse und Darstellung der KDSA-Daten können Sie online verfolgen unter https://github.com/cysouw/KDSA.
Literatur
Heeringa, Wilbert. 2004. Measuring dialect pronunciation differences using Levenshtein distance. Rijksuniversiteit Groningen dissertation. https://research.rug.nl/en/publications/measuring-dialect-pronunciation-differences-using-levenshtein-dis
Kleiner Deutscher Sprachatlas. 1984–1999. Dialektologisch bearbeitet von Werner H. Veith, computativ bearbeitet von Wolfgang Putschke und Lutz Hummel. 4 Bände. Tübingen: Max Niemeyer Verlag.
Diesen Beitrag zitieren als:
Cysouw, Michael. 2022. Wenkerbögen neu kartiert. Sprachspuren: Berichte aus dem Deutschen Sprachatlas 2(6). https://doi.org/10.57712/2022-06.