Die Berliner/innen sprechen alle schnell, die Schweizer/innen langsam (und die Berner/innen erst!!). In Hannover spricht man klar und deutlich, in Sachsen wird genuschelt und die Norddeutschen (vonne waterkant) sind eben sehr einsilbig. Solche und weitere subjektive Alltagstheorien bestehen zuhauf und sind immer wieder Grundlage für (regionalsprachliche) Abgrenzungsversuche zu den „Anderen“. Oft wird dabei auch auf gängige (oder manchmal sogar nur ad hoc gebildete?) Stereotype zurückgegriffen, bei denen diese Andersartigkeit der Anderen auf ihre spezielle Art zu sprechen zurückgeführt werden soll. Aber stimmen solche Annahmen? Gibt es überhaupt Regionen, in denen nachweislich schneller oder langsamer gesprochen wird? Und gibt es wirklich Regionen, in denen die Leute stärker „nuscheln“ und verschliffener sprechen als andere? Und müsste das dann nicht auch zusammenhängen, müssten nicht die Schnellsprecher/innen auch automatisch verschliffener sprechen?
Daten und makroskopische Zusammenhänge
Die obigen Karten in Abb. 1 ermöglichen zunächst einen Ansatz zur Beantwortung einiger dieser Fragen. Die Datengrundlage hierfür bilden Aufnahmen von 327 Sprechern (m.) aus 165 Orten jener Länder und Regionen in Mitteleuropa, in denen Deutsch Amtssprache ist, also Deutschland, Österreich, Schweiz, Ostbelgien, Luxemburg und Südtirol (Autonome Provinz Bozen, Italien). Es handelt sich um die Nordwind und Sonne-Aufnahmen aus dem Deutsch heute-Korpus des IDS Mannheim (vgl. Kleiner 2015), bei denen die Sprecher den Text in normalem und schnellem Tempo vorlesen mussten, wobei in Abb. 1 nur die normalen Lesungen einbezogen werden. Die Sprecher sind in diesem Fall allesamt Schüler der Abitur- bzw. Maturaklassenstufen (17–20 J.), welche in dem repräsentierten Orten oder der nächsten Umgebung aufgewachsen sind und keine spezielle sprecherische Ausbildung genossen haben.
Diese Aufnahmen wurden im Rahmen des Leipziger SpuRD-Projektes (vgl. Hahn/Siebenhaar 2016, 2019b) zunächst über das onlinebasierte Tool WebMaus automatisch vorsegmentiert (vgl. Kisler et al. 2017) und anschließend auf Segment- und Wortebene manuell in Praat (Boersma/Weenik 2020) hinsichtlich der Annotation und der Zeitmarkensetzung angepasst. Aus diesen Daten lässt sich nun (u.a.) die Anzahl der tatsächlich realisierten Segmente, deren konkrete Dauern und – aus der Summe dieser Segmentdauern – die Gesamtartikulationsdauer ermitteln, welche die Basis für die Kartierungen in Abb. 1 bilden.
Die linke Karte (ArtDur in s) gibt die gesamte Artikulationsdauer in Sekunden an. Das ist – als die Summe aller Segmentdauern – jene Zeit, die die untersuchten Sprecher benötigten, um den für alle identischen Text vorzulesen, wobei hier alle Pausenzeiten und vereinzelte Versprecher nebst Reparaturen herausgerechnet wurden. Die mittlere Karte gibt die Artikulationsrate (AR in Segm/s) an, die sich berechnet aus der Anzahl der tatsächlich realisierten Lautsegmente geteilt durch die Artikulationsdauer. Diese beiden Karten zeigen also zwei Möglichkeiten, das Tempo von Gesprochenem zu quantifizieren und abzubilden. Schließlich gibt die rechte der drei Karten über den Segmentelisionsgrad (SEG) prozentual an, wie viele der im Text vorgesehenen Lautsegmente im Durchschnitt ausgelassen werden, wie viel von den kanonischen zu erwartenden Segmenten also verschliffen wird.
| Variable | N_Sprecher | Mittelwert | Std.-Abw. | Minimum | Maximum |
| ArtDur in s | 327 | 31,4 | 2,35 | 26,0 | 41,8 |
| AR in Segm/s | 327 | 17,3 | 1,10 | 13,3 | 20,1 |
| SEG in % | 327 | 12,8 | 3,70 | 1,0 | 22,0 |
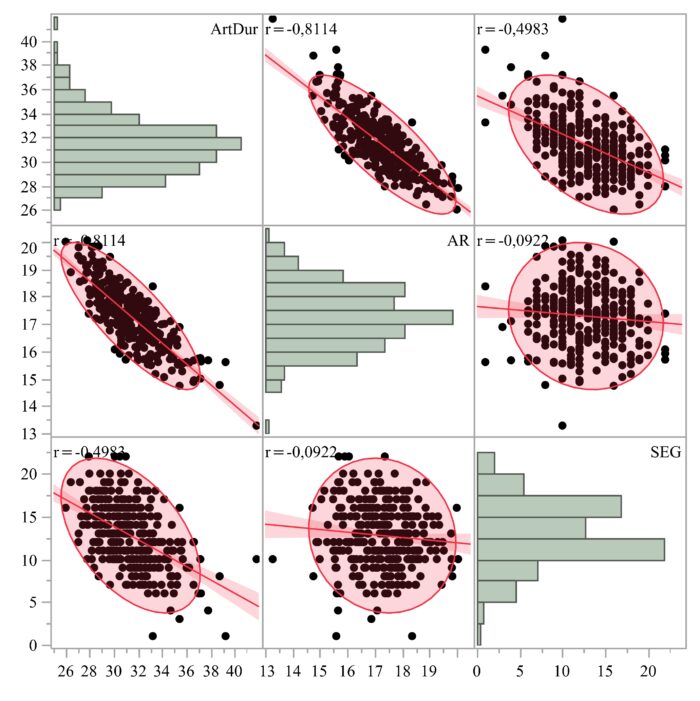
Bevor wir uns die sprachräumlichen Strukturen genauer besehen, blicken wir hier noch einmal auf die Gesamtdaten. Wie liegen also die allgemeinen Verhältnisse? Abb. 2 zeigt die Zusammenhänge und Distributionen, Tab. 1 gibt die deskriptiven Statistiken zu diesen drei makroskopischen, d.h. über das Textganze gemittelten Messvariablen. ArtDur und AR, als Maße des Tempos des Gesprochenen, korrelieren sehr stark negativ mit einander (r= ‑0.81): Je geringer die Artikulationsrate ist, desto höher ist die Artikulationsdauer (“Je schneller die Laute gebildet werden, desto eher ist man fertig mit dem Text.”). Die Artikulationsdauer wird aber erwartungsgemäß auch vom Grad der Segmentelision beeinflusst. Diese Maße korrelieren ebenfalls negativ und noch auf mittlerem Niveau (r= ‑0.5): Je höher also die Segmentelisionswerte, desto geringer die Artikulationsdauer (“Je mehr Laute weggelassen werden, desto eher ist man fertig mit dem Text.”). AR und SEG hingegen korrelieren nicht miteinander (r= ‑0.09): Die durchschnittliche Anzahl realisierter Segmente pro Zeit (bzw. reziprok auch die durchschnittlichen Lautdauern) und die Elisionsverhältnisse stehen demnach in keinem allgemeinen Zusammenhang. Die Antwort auf die Frage, ob Sprechtempo und Ausspracheverschleifungen zusammenhängen, ist demnach ein: “kommt darauf an!” Je nachdem, welches Sprechtempo-Äquivalent angesetzt wird, kommt man auf unterschiedliche statistische Zusammenhänge (vgl. hierzu auch Trouvain 2004, Weiss 2008 und Lanwer 2015).
Tempo und Segmentrealisierung sind regional verschieden konfiguriert
Mit Blick auf die Karten in Abb. 1 lässt sich dieses Beziehungsgeflecht nun aber noch etwas entwirren. Links und in der Mitte sind die Sprechtempo-Äquivalente abgebildet, die ihren starken Zusammenhang erst auf den zweiten Blick preisgeben, da die Farbgebung wert- und nicht inhaltsorientiert ist. D.h. je brauner ein Areal, desto höher sind die dort gemessenen Werte („Berge“) und je blauer ein Areal, desto niedriger sind die dortigen Werte („Täler“) (zur Methodik im Detail vgl. Hahn/Siebenhaar 2019b, Hahn i. Vorb.). Das Beispiel der Schweiz und des alemannischen Raumes kann das verdeutlichen: In der linken Karte zur ArtDur ist dieses Areal braun, die Sprecher dort zeigen also hohe Artikulationsdauern. In der mittleren Karte ist derselbe Bereich eher blau, die Sprecher haben folglich Artikulationsraten am unteren Ende der Skala. In beiden Fällen kann man aber daraus schließen, dass insbesondere die Schweizer „langsamer“ lesen. So verhält es sich auch in den meisten anderen Gebieten: da, wo sich hohe Artikulationsraten finden, ist ebenfalls die Artikulationsdauer geringer und vice versa. Es zeigen sich aber Regionen wie der nordniederdeutsche Raum, wo paradoxerweise im Mittel schnell (ArtDur) und langsam (AR) gelesen wird, je nach dem welches Maß man nimmt (vgl. Hahn i. Vorb.). Der Vergleich dieser beiden Karten mit jener für den SEG offenbart das komplexe Zusammenspiel dieser Faktoren. Das Beispiel der Schweiz zeigt zunächst den erwartbaren Zusammenhang: hohe Artikulationszeit, niedrige Artikulationsrate und ebenfalls eine niedrige Elisionsrate. Die Schweizer Sprecher produzieren die Laute demnach durchschnittlich länger und sie verschleifen im Vergleich zur kanonischen Grundlage auch weniger Lautsegmente, weshalb sie letztlich deutlich länger brauchen, den Text zu lesen. Eine etwas andere Situation zeigt sich im nord- und mittelbairischen Raum. Hier benötigen die Sprecher ebenfalls mehr Zeit als der Durchschnitt (hell- und dunkelbraune Färbung = 31,7–34,3 s > MWgesamt = 31,4 s). Die Artikulationsraten und damit wieder die mittleren Lautdauern liegen aber eher im mittleren Bereich um 16,5–16,7 Segm/s. Der SEG liegt aber ähnlich wie bei den Schweizer Sprechern: auch hier wird wenig verschliffen (nur ca. 8 – 10 %). Wiederum eine andere Konstellation ergibt sich im südbairischen Gebiet: nämlich eine mittlere ArtDur mit einer sehr hohen AR, jedoch kombiniert mit einem niedrigen SEG. Die Karten ließen sich an dieser Stelle auch für die anderen Regionen des Deutschen noch im Detail betrachten, für die Darstellung des regional variierenden Zusammenhangs zwischen Sprechtempo-Äquivalenten und Segmentelision mag das Beispiel des oberdeutschen Raumes hier aber genügen. Man kann aussagen, dass die regionalen Verhältnisse bei ausschließlich statistisch-makroskopischer Betrachtung der Gesamtdaten (Abb. 2) in gewisser Weise nivelliert werden, da die gesprochene Sprache in den Regionen des Deutschen in temporal-realisationaler Hinsicht unterschiedlich konfiguriert sind. Eine Situation, die letztlich erst die sprachgeografische Auswertung konkreter Messungen sichtbar macht.
Erklärungsansatz zum Nord-Süd-Kontrast
Der Blick auf Abb. 1 lässt – bei aller kleinräumigen Varianz, die hier schon wegen der geringeren Ortsnetzdichte vernachlässigt werden muss – sowohl für die ArtDur als auch für den SEG einen deutlichen Nord-Süd-Kontrast hervortreten. Wenigstens für den Grad an Segmentverschleifungen kann damit der schon von Meinhold (1973) und Kohler (2001) vermutete Nord-Süd-Kontrast für Reduktionsprozesse im Deutschen nun auch empirisch nachgewiesen werden. Dieser Gegensatz zwischen dem Norden, wo weniger Zeit zum Lesen des Textes benötigt und mehr verschliffen wird, und dem Süden, wo man mehr Zeit benötigt und weniger verschleift, lässt sich verstehen, wenn man die regionale Verteilung des SEG vor dem Hintergrund regional variierender vertikaler Sprechlagenspektren betrachtet (die Diskussion zusammenfassend vgl. Schmidt 2017). Denn diesen liegt u.a. auch eine regionalspezifisch ausgeprägte Alltagsrelevanz der hier untersuchten Sprechlage, dem intendierten Standard, zugrunde. Diese Situation spiegelt sich auch in der Verteilung der phonetischen Standarddifferenzen regionaler Vorleseaussprache (vgl. Kehrein 2008: 329) wider, mit denen der Segmentverschleifungsgrad daher nicht zufällig räumlich auch sehr stark korreliert. Vereinfacht ausgedrückt verhalten sich die Sprecher dieser Generation im Nordwesten Deutschlands in sprachlicher Hinsicht aufgrund der phonetischen Nähe zwischen der Standardaussprache und ihrem Regiolekt, über den sie ausschließlich verfügen, entsprechend auch kolloquialer in der Lesesituation, was dann zu einem höheren Segmentelisionsgrad führt. Ein kolloquiales sprachliches Verhalten meint hier, dass die Sprecher das stilistische Niveau ihrer Aussprache zwischen alltäglichen und formaleren, Standardsprache evozierenden Situationen weniger variieren und dabei insgesamt eine geringere Artikulationspräzision anstreben. Im Norden und Nordwesten des Untersuchungsraums finden sich bedeutend häufiger Realisierungen wie [baIn=] ‚beiden‘, [dEsso] ‚desto‘, [van@R6] ‚Wanderer‘ oder [zaIn] ‚seinen‘, bei denen v.a. inlautende Plosive mit dem phonetischen Umfeld assimilieren und Nebensilben durch Schwa-Elision und Assimilation der dadurch entstehenden Konsonantencluster abgebaut werden. (Was dann tatsächlich häufiger zur Einsilbigkeit führt…) Die vertikalen Variationsspektren gehen aber, je weiter südlich man schaut, weiter auseinander. Die Alltagssprache ist dort entsprechend auch standardferner und die phonetischen Distanzen zum Standard steigen an. Die Sprecher im Süden verhalten sich in dieser Situation weniger kolloquial und orientieren sich stärker an der kanonischen Grundlage (sie bemühen sich sozusagen mehr), was in segmental-reduktiver (nicht qualitativer!) Hinsicht ein ‚buchstabentreueres‘ Lesen zur Folge hat. Letzteres zeigt sich insbesondere bei der Realisierung von Schwa in Nebensilben des Typs Nasal-Schwa-Nasal wie in einen, seinen oder zwingen die im (ost-)oberdeutschen Raum in dieser Situation noch kodifizierungsgemäß (vgl. Duden Aussprachewörterbuch: Kleiner a. 2015, 39–40) realisiert werden, während sie im gesamten nord- und mitteldeutschen Raum nicht mehr oder nur noch sporadisch gebildet werden (vgl. Hahn/Siebenhaar 2019a).
Während sich die Werte für die Elisionsraten gut über die variationslinguistischen Bedingungen der Situation erklären lassen, scheinen die mittleren Lautdauerverhältnisse, die sich in der Artikulationsrate ausdrücken, dialektal oder regiolektal bedingt zu sein. Mit Ausnahme der Schweizerdeutschen Dialekte (vgl. zusammenfassend Siebenhaar 2015, Leemann 2017) fehlen leider bislang die Vergleichsgrundlagen umfassender dialektaler oder regiolektaler Dauermessungen.
Zur tempounabhängigen progressiven Nasalassimilation in Nebensilben
Über den genannten unterschiedlichen Alltäglichkeitsgrad der Standardsprache lässt sich folglich ein wichtiger Teil der Variation nachvollziehen. Im Folgenden soll aber ein Beispiel betrachtet werden, das sich dieser Erklärung entzieht und aufzeigt, dass auch dialektale Prägung der Aussprache – sozusagen durch artikulatorisches Training – dazu führen kann, gewisse Realisationsphänomene über die Varietätengrenzen hinweg zu realisieren. Hierbei handelt es sich um die Tendenz, finale Nasale in Nebensilben nach Schwa-Elision an den Artikulationsort des vorausgehenden Plosivs anzugleichen. Auch hier sollte man meinen, dass schnelleres Sprechen zu höheren Assimilationstendenzen führt. Ein Zusammenhang zwischen den Sprechtempo-Äquivalenten und der Häufigkeit assimilierter Belege (Nass) zeigt sich aber in den SpuRD-Daten nicht. Für die folgenden Berechnungen und Kartierungen einbezogen wurden die Belegwörter Augenblicken, zugeben und wenigen, je für das schnelle und normale Lesetempo zusammengenommen, sodass maximal acht Belege pro Sprecher vorliegen. Die Korrelation nach Pearson zwischen ArtDur und Nass beträgt r= ‑0.19 für normales und r= ‑0.05 für schnelles Lesen, für die AR und Nass jeweils r= +0.13. Das Ausmaß an Assimilationen in dieser Position hängt folglich nicht mit dem Tempo des Gesprochenen zusammen.
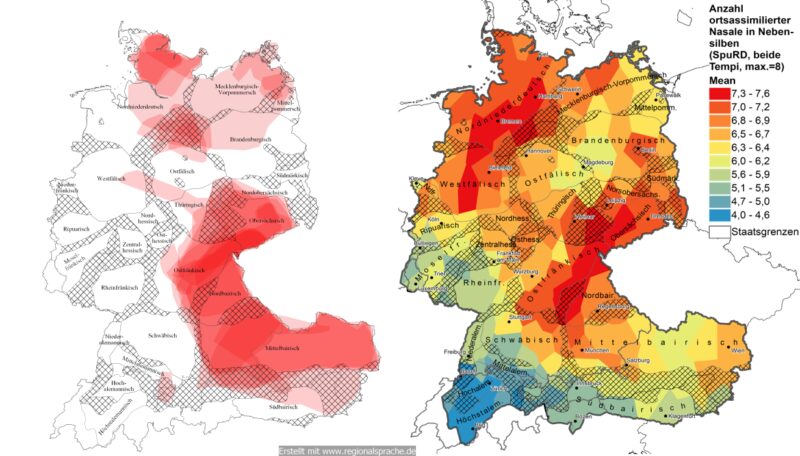
In Abb. 3 lassen sich nun zwei Karten miteinander vergleichen. Zum einen die Verteilung von auf Assimilation von -n hinweisenden Schreibungen (also m- bzw. ng-Schreibungen) aus dem Kleinen Deutschen Sprachatlas (KDSA, Veith et al. 1984) in den Trägerwörtern Abend, geblieben, oben, treiben, gestorben, Augenblickchen, fliegen und liegen (Kartennr.: 23, 24, 27, 28, 33, 99–101) die über das REDE SprachGIS (Schmidt et al. 2008ff.) zusammengetragen und überblendet wurden. Je intensiver die Farben in dieser Abbildung sind, desto häufiger finden sich in der betreffenden Region assimilierte Belege im KDSA. Zum anderen werden die oben genannten Häufigkeiten ortsassimilierter Nasale für Belege aus dem SpuRD-Projekt ausgezählt und kartiert (rechte Karte in Abb. 3). Auch hier verweist ein intensiveres Rot auf häufigere Vorkommen assimilierter Belege (zu den Details vgl. Hahn i. Vorb.: Kap. 5.3.2). Kurzum: die Regionen mit der höchsten Dichte an assimilierten Belegen sind in beiden Fällen weitgehend kongruent. Es ergeben sich jeweils ein norddeutsches Areal mit einem Zentrum in etwa zwischen Lüneburger Heide und Holstein sowie ein verbundenes obersächsisches, ostfränksiches, nord- und mittelbairisches Areal, in denen die Assimilationstendenzen für diese Position stärker sind als in den anderen Regionen des Deutschen. Die dialektalen Gegebenheiten dieser Assimilationstendenz in den Nebensilben zeigen sich in diesem Fall also auch unabhängig vom jeweiligen Sprechtempo, das sich, wie wir weiter oben gesehen haben, zwischen dem nord- und süddeutschen Raum erheblich unterscheidet.
Fazit
Sprechtempo und phonetische Reduktion (Verschleifungen) zeigen jeweils regional eigenständige Variation, obwohl sie nachvollziehbar eng miteinander verzahnt sind. Dafür verantwortlich sind, was das hier ausgewertete Material angeht, die regional differenten variationslinguistischen Bedingungen für den intendierten Standard auf der einen Seite sowie die dialektalen bzw. regiolektalen Artikulationsgewohnheiten (Assimilationstendenzen, timing-Strukturen usw.) auf der anderen Seite. Die eingangs erwähnten Alltagstheorien beziehen sich in aller Regel auch auf das alltägliche Sprechen bzw. auf medial häufig vermitteltes, stereotypisiertes Sprechen gewisser Sprecher/innengruppen. Unter Rückgriff auf standardintendierte Leseaussprache lassen sich diese hier nun leider nicht umfassend aufklären. Die Schweizer Aufnahmen bspw. sind im Mittel zwar wirklich deutlich langsamer als bei den übrigen Deutschsprachigen. Aber auch hier findet sich bedeutende Binnenvariation v.a. zwischen Bernern und Wallisern, die auch Siebenhaar (2015) und Leemann (2017) für Dialektaufnahmen beschreiben. Das ganze Feld dialektaler und regiolektaler Dauervariation ist – mit Ausnahme der Schweiz – für das Deutsche noch nicht weiter erforscht. Dennoch ist nun eine Interpretationsfolie für den gesamten deutschsprachigen Raum vorhanden, mit der weitere Vergleiche und Relativierungen von Messungen für das Deutsche unternommen werden können.
Der Beitrag ist sozusagen ein Teaser für meine Dissertation, die im Frühjahr 2022 in der Reihe Deutsche Dialektgeographie (DDG) bei OLMS erscheinen wird, und ein Resultat des 2018–2021 von der DFG geförderten Projektes „Sprechtempo und Reduktion im Deutschen (SpuRD)“ ist, das an der Universität Leipzig unter der Leitung von Beat Siebenhaar durchgeführt wurde; DFG-Fördernummer: SI 1656/5–1.
Literatur
Boersma, Paul und David Weenik (2020): Praat : doing phonetics by computer. Version 6.1.13. www.praat.org (19.04.2020).
Hahn, Matthias (in Vorb.): Sprechgeschwindigkeit und Reduktion im deutschen Sprachraum. Eine Untersuchung zur diatopischen Variation standardintendierter Vorleseaussprache. Zugl. Leipzig, Univ., Dissertation, 2021. Hildesheim [u. a.]: Olms (Deutsche Dialektgeographie).
Hahn, Matthias und Beat Siebenhaar (2019b): „Spatial Variation of Articulation Rate and Phonetic Reduction in Standard-intended German.“ In: Calhoun, Sasha, Paola Escudero, Marija Tabain und Paul Warren (Hg.): Proceedings of the 19th International Congress of Phonetic Sciences, Melbourne, Australia. Melbourne: 2695–2699.
Hahn, Matthias und Beat Siebenhaar (2019a): „Schwa unbreakable – Reduktion von Schwa im Gebrauchsstandard und die Sonderposition des ostoberdeutschen Sprachraums.“ In: Habermann, Mechthild, Sebastian Kürschner und Peter O. Müller (Hg.): Dialektale Daten: Erhebung – Aufbereitung – Auswertung. Hildesheim: Olms: 215–236. (=Germanistische Linguistik 241–243).
Hahn, Matthias und Beat Siebenhaar (2016): “Sprechtempo und Reduktion im Deutschen (SpuRD)”. In: Jokisch, Oliver (Hg.): Elektronische Sprachsignalverarbeitung 2016. Dresden: TUDpress: 198–205. (=Studientexte zur Sprachkommunikation 81)
Kisler, Thomas, Uwe Reichel und Florian Schiel (2017): „Multilingual processing of speech via web services“. Computer Speech & Language 45: 326–347.
Kleiner, Stefan (2015): „‘Deutsch heute‘ und der Atlas zur Aussprache des deutschen Gebrauchsstandards“. In: Kehrein, Roland, Alfred Lameli und Stefan Rabanus (Hg.): Regionale Variation des Deutschen. Projekte und Perspektiven. Berlin, München, Boston: Walter de Gruyter: 489–518.
Kleiner, Stefan, Ralf Köbel und Max Mangold (2015): Duden: Das Aussprachewörterbuch. 7., komplett überarb. u. aktual. Aufl. Berlin: Dudenverlag. (=Duden 6).
Kohler, Klaus J. (2001): „The investigation of connected speech processes. Theory, method, hypotheses and empirical data.“. In: Kohler, Klaus J., Felicitas Kleber und Benno Peters (Hg.): Prosodic Structures in German Spontaneous Speech. Arbeitsberichte des Instituts für Phonetik der Universität Kiel (AIPUK 35). Kiel: 1–32.
Lanwer, Jens Philipp (2015): „Allegro oder usuell? Zum Status sogenannter ‚Allegroformen‘ aus Sicht einer gebrauchsbasierten Linguistik.“. In: Elmentaler, Michael, Markus Hundt und Jürgen Erich Schmidt (Hg.): Deutsche Dialekte. Konzepte, Probleme, Handlungsfelder; Akten des 4. Kongresses der Internationalen Gesellschaft für Dialektologie des Deutschen (IGDD). Stuttgart: Steiner: 169–190.
Leemann, Adrian (2017): „Analyzing geospatial variation in articulation rate using crowdsourced speech data“. Journal of Linguistic Geography 2/4: 76–96.
Meinhold, Gottfried (1973): Deutsche Standardaussprache: Friedrich-Schiller-Universität. (=Wissenschaftliche Beiträge der Friedrich-Schiller-Universität Jena).
Schmidt, Jürgen Erich, Joachim Herrgen, Roland Kehrein und Alfred Lameli (2008ff.): Regionalsprache. de (REDE). Forschungsplattform zu den modernen Regionalsprachen des Deutschen. Teil 6: REDE SprachGIS – Das forschungszentrierte sprachgeographische Informationssystem von Regionalsprache.de. <regionalsprache.de/SprachGIS/Map.aspx> (17.09.2021).
Schmidt, Jürgen Erich (2017): „Vom traditionellen Dialekt zu den modernen deutschen Regionalsprachen“. In: Deutsche Akademie für Sprache und Dichtung / Union der deutschen Akademien der Wissenschaften (Hg.): Vielfalt und Einheit der deutschen Sprache. Zweiter Bericht zur Lage der deutschen Sprache. Tübingen: Stauffenburg: 105–143.
Siebenhaar, Beat (2015): „Quantitative Ansätze zu einer Sprachgeographie der schweizerdeutschen Prosodie“. In: Kehrein, Roland, Alfred Lameli und Stefan Rabanus (Hg.): Regionale Variation des Deutschen. Projekte und Perspektiven. Berlin, München, Boston: Walter de Gruyter.
Trouvain, Jürgen (2004): Tempo variation in speech production: Implications for speech synthesis. Saarbrücken: Institut für Phonetik, Universität des Saarlandes. (=Phonus 8).
Veith, Werner H., Wolfgang Putschke und Lutz Hummel (1984): Kleiner deutscher Sprachatlas, Bd. 1. Konsonantismus: Plosive. Tübingen: Niemeyer.
Weiss, Benjamin (2008): Sprechtempoabhängige Aussprachevariationen. Berlin, Humboldt-Universität zu Berlin, Dissertation.
Wiesinger, Peter (1983): „Die Einteilung der deutschen Dialekte“. In: Besch, Werner et al. (Hg.): Dialektologie. Ein Handbuch zur deutschen und allgemeinen Dialektforschung. Berlin: Walter de Gruyter: 807–900.
Diesen Beitrag zitieren als:
Hahn, Matthias. 2021. Zum Zusammenhang von Sprechtempo und Ausspracheverschleifungen im deutschen Sprachraum. Sprachspuren: Berichte aus dem Deutschen Sprachatlas 1(10). https://doi.org/10.57712/2021-10.